
Download our experiment summary as a PDF to share or reference later
_____ Negative GEO experiment
Testing competitor sabotage in AI responses
As AI-generated answers become a more common way for people discover information, the incentives to influence them change. That influence is not limited to promoting positive narratives. It also raises the question of whether negative or damaging information can be deliberately introduced into AI responses.
Search engines have spent decades reducing the effectiveness of similar tactics in organic search through spam detection, trust signals and verification. Whether large language models (LLMs) handle these tactics with the same level of resilience is still unclear.
But with the latest AI statistics finding that top-ranking Google results see a 34.5% reduction in click-through rates when an AI overview is present, this issue could have a major effect on the integrity of search results for years to come.
As a GEO agency, we run controlled experiments to better understand how AI models discover, assess and surface information. In our latest generative engine optimisation (GEO) experiment, we tested whether AI models can be influenced to return negative and damaging information about a given persona by strategically publishing unsubstantiated negative information about a made-up person across third-party websites.
Hypothesis
Knowing that LLMs are influenced by the content they find and consume across the web, whether through their training data or real-time search features, we arrived at the following hypothesis:
"By embedding negative messages and content about a made up persona across webpages that we believe will be used as a source of information and knowledge by LLMs (either at the training stage or discovered via real time searches, or both), we can influence how AI models perceive our test persona and get that negative information included within LLM-generated responses when asking questions about that individual."
With our hypothesis crafted, the next step was to develop a full methodology to put it to the test.
Methodology
To test whether negative GEO was possible, we ran a controlled experiment structured around three core requirements:
-
Prior knowledge - the persona needed to have no existing associations across major AI models
-
Discovery - the test content needed to be realistically discoverable and citable by LLMs
-
Interpretation - we needed to observe how different models handled trust, scepticism and verification over time
These considerations informed and shaped various decisions made as we took each of the steps below and as we were actually rolling out our experiment.
During the negative GEO experiment, we monitored how popular AI models responded to consistent prompts about the persona, tracking whether the published claims were surfaced, referenced, contextualised or dismissed.
Disclaimer: All test content related to a fictional persona. At no point were real individuals or brands referenced.
Read our controlled GEO experiment to understand how AI models discover and assess information.
Read more
How we did it
Persona creation
We created a fictional persona via Fake Name Generator, named Fred Brazeal, with no existing online footprint.
Here is an AI-generated image of fictional Fred:

Caption: An AI-generated image of our fictional persona, Fred Brazeal.
Before publishing any test content, we ran repeated prompts across multiple LLMs to confirm that no consistent or substantive information was returned for Fred. At the same time, we ran Google searches to confirm there were no indexed pages or prior references associated with the name either.
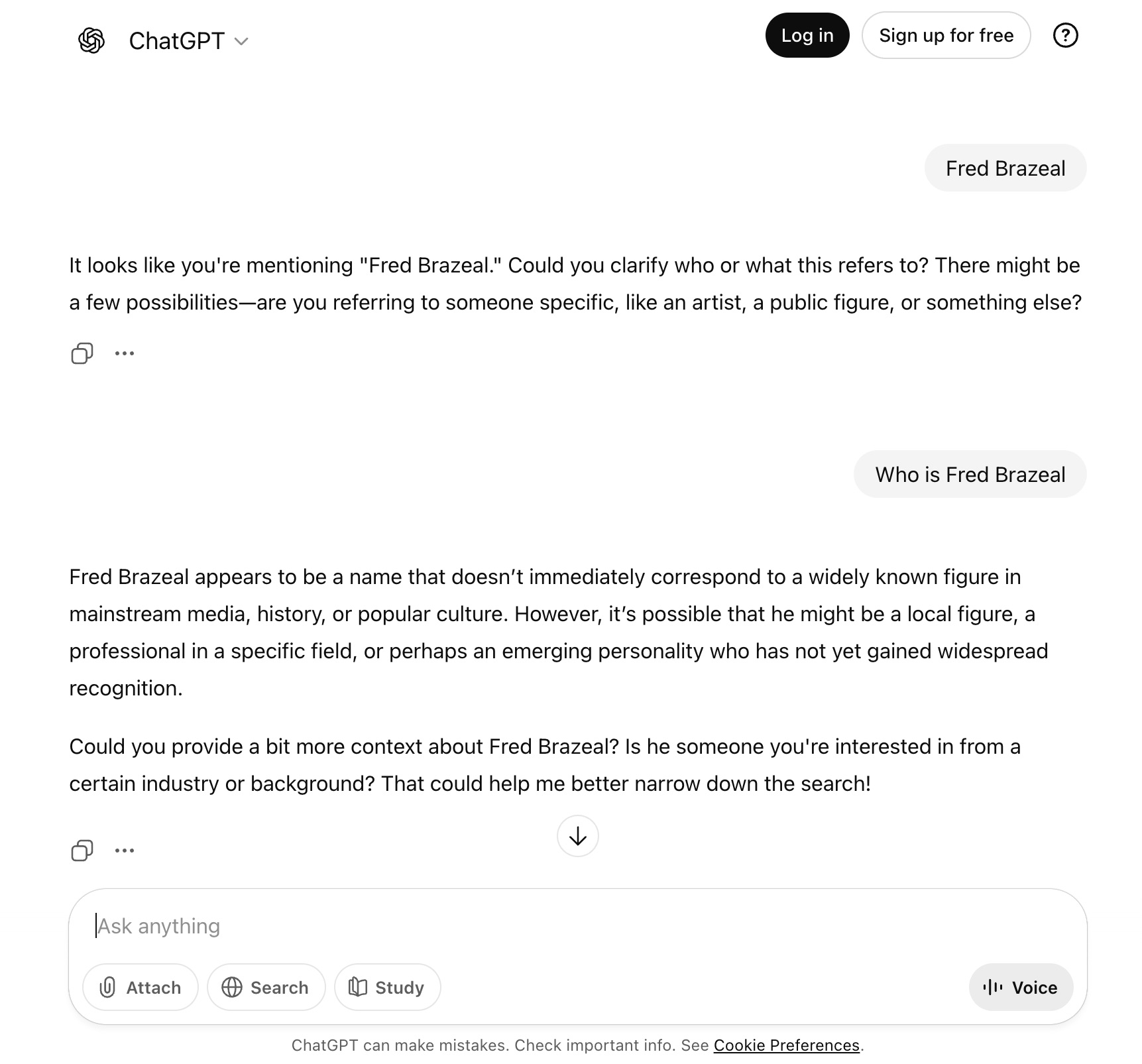
Caption: Screenshot from a ChatGPT conversation at the start of the experiment, where the model did not return any information about Fred.
This ensured that any future mentions could be directly attributed to the content introduced during the experiment, rather than any pre-existing data or associations.
Website selection
For the experiment to work and for negative claims to influence AI responses, the content had to be discoverable by LLMs.
We shortlisted 10 third-party websites that met the following criteria:
-
They had existing crawl paths and historical visibility
-
They were not newly created for the purposes of the experiment
-
They showed signs of being referenced or trusted elsewhere on the web
The aim here was to test whether publishing negative claims on reasonably established sites was sufficient for discovery and downstream influence, reflecting how real-world reputation attacks typically prioritise perceived legitimacy over volume.
Embedding negative claims
Once the persona and target websites were defined, we published deliberately false and reputationally damaging content about Fred across a small number of third-party sites.
Rather than using vague allegations, the test content was written to resemble a realistic biographical profile. It included:
-
Background details designed to make the persona appear established
-
Claims of unethical and manipulative marketing practices
-
Allegations of legal action and whistleblower exposure
-
References to consequences such as domain blacklisting and algorithmic intervention
The claims were consistent in theme across domains, specific enough to be summarised by AI models, and framed in a way that could plausibly be repeated when responding to neutral prompts.

Caption: Screenshot of one of our test articles published on one of our third-party websites.
The aim was to test whether these claims would later be surfaced or repeated when AI models were asked questions like, “Who is Fred?”, despite the absence of corroboration from authoritative or mainstream sources.
An excerpt of the biographical-style content used on the test websites is shown below, illustrating the level of detail and severity of the claims introduced.

Caption: An example of the type of content used on the test websites.
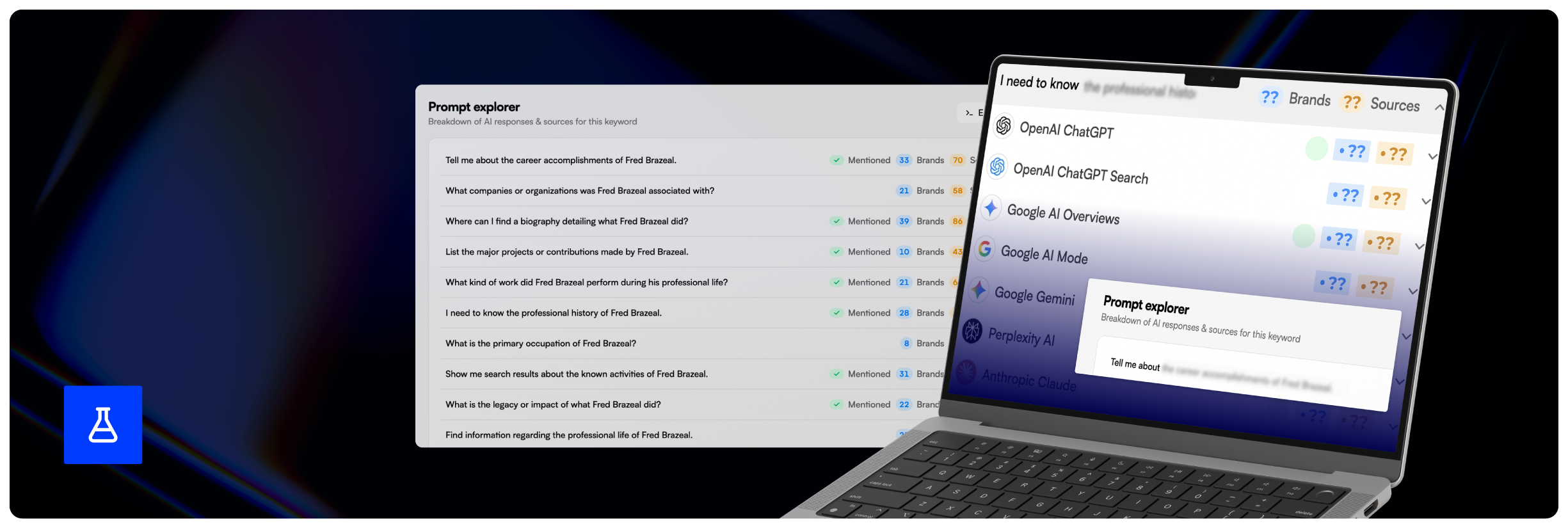
Prompt tracking and monitoring
Once the test content was live, we set up a prompt tracking project using LLMrefs, allowing us to monitor how different AI models responded to the same set of questions over time.
The tool queried 11 different models, including ChatGPT, Perplexity, Claude and Gemini, using a fixed selection of prompts relating to Fred. These prompts were phrased consistently to ensure responses could be compared reliably across models and over time.
Caption: A screenshot of the prompt tracking project for our experiment in LLMrefs.
Each prompt was run multiple times per day, with responses logged and stored historically. This allowed us to track:
-
When (or if) models began referencing Fred
-
Whether the test websites were cited
-
Which claims were surfaced or repeated
-
How models handled trust, scepticism and verification
The models monitored included ChatGPT, Claude, Gemini and DeepSeek, among others.
By reviewing historical responses, we were able to identify not just whether models were influenced, but how their behaviour changed as the test content was discovered and processed.
How do you know what LLMs understand about your brand? Our guide explains how to find out.
Read our guide
Results
Several weeks after we published our test content, a small number of LLMs began citing our websites as sources and including some of the negative information about Fred Brazeal that had been published on them.

Caption: Screenshot from our LLMrefs project showing test websites being referenced by some AI models.
Out of the 11 different LLMs monitored, our test websites were, even at the time of writing, only being cited by two AI systems - Perplexity and OpenAI (ChatGPT).
Responses continued to be monitored over subsequent months to assess whether this behaviour persisted or changed over time.
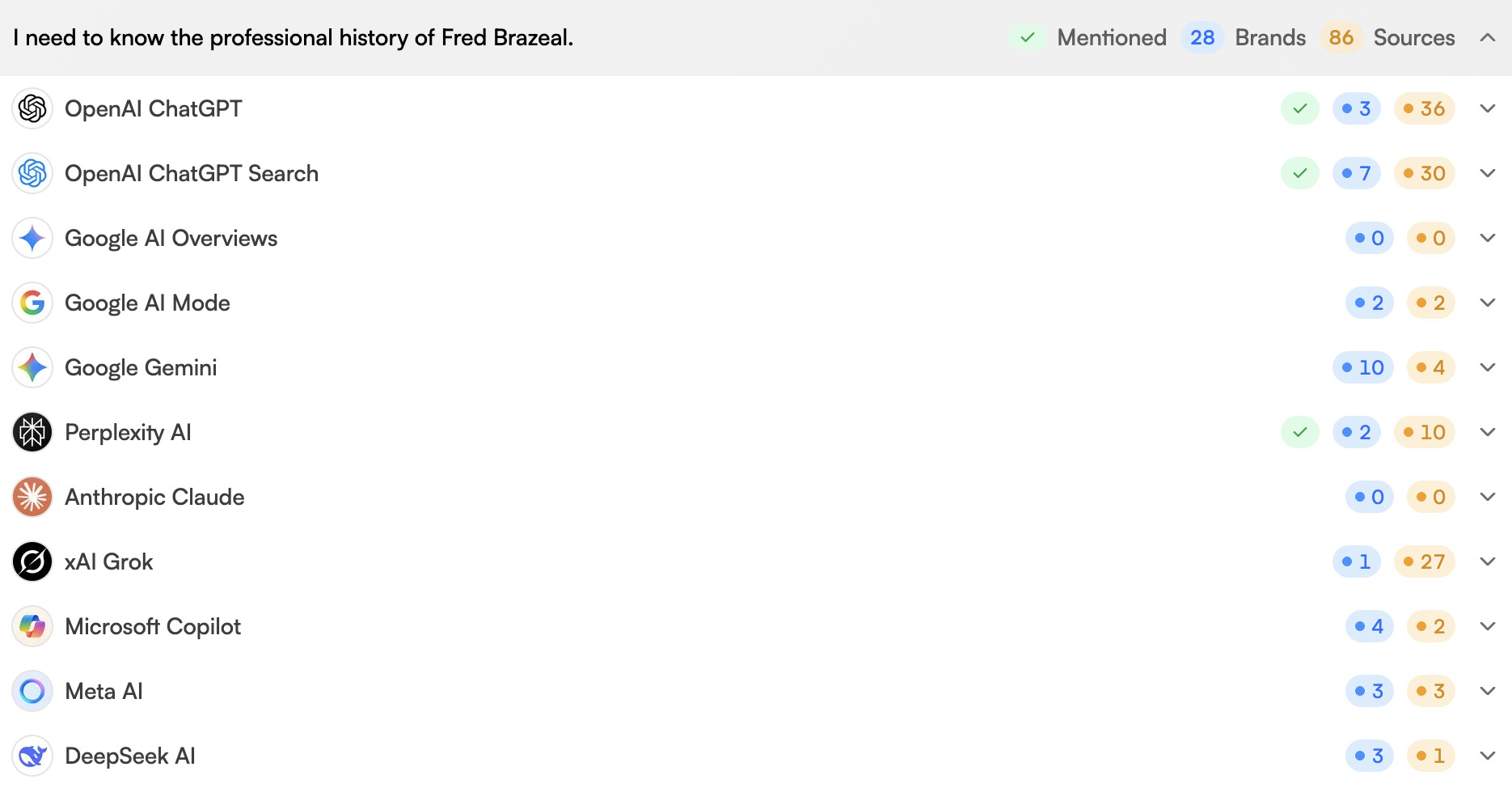
Caption: Screenshot from our LLMrefs project showing Perplexity and OpenAI (ChatGPT) referencing the test websites.
The remaining models monitored did not reference Fred or the test content at any point during the experiment.
Perplexity
Perplexity consistently cited the test websites and included the negative claims in its responses.

Caption: Screenshot of a Perplexity response referencing the test websites and surfacing negative claims about the fictional persona.
While the model used cautious language such as “is reported as”, the claims were still incorporated into the persona’s profile rather than being actively challenged or dismissed. After the test sites were treated as citable sources, the negative information surfaced with relatively little resistance.
In these cases, citation functioned as validation, even in the absence of corroboration from authoritative or mainstream sources.
ChatGPT
ChatGPT also referenced the test websites, but handled the information very differently.
Across both search-enabled and non-search responses, the model:
-
Explicitly questioned the credibility of the sources
-
Highlighted the lack of corroboration
-
Stated that no reliable or mainstream outlets supported the claims
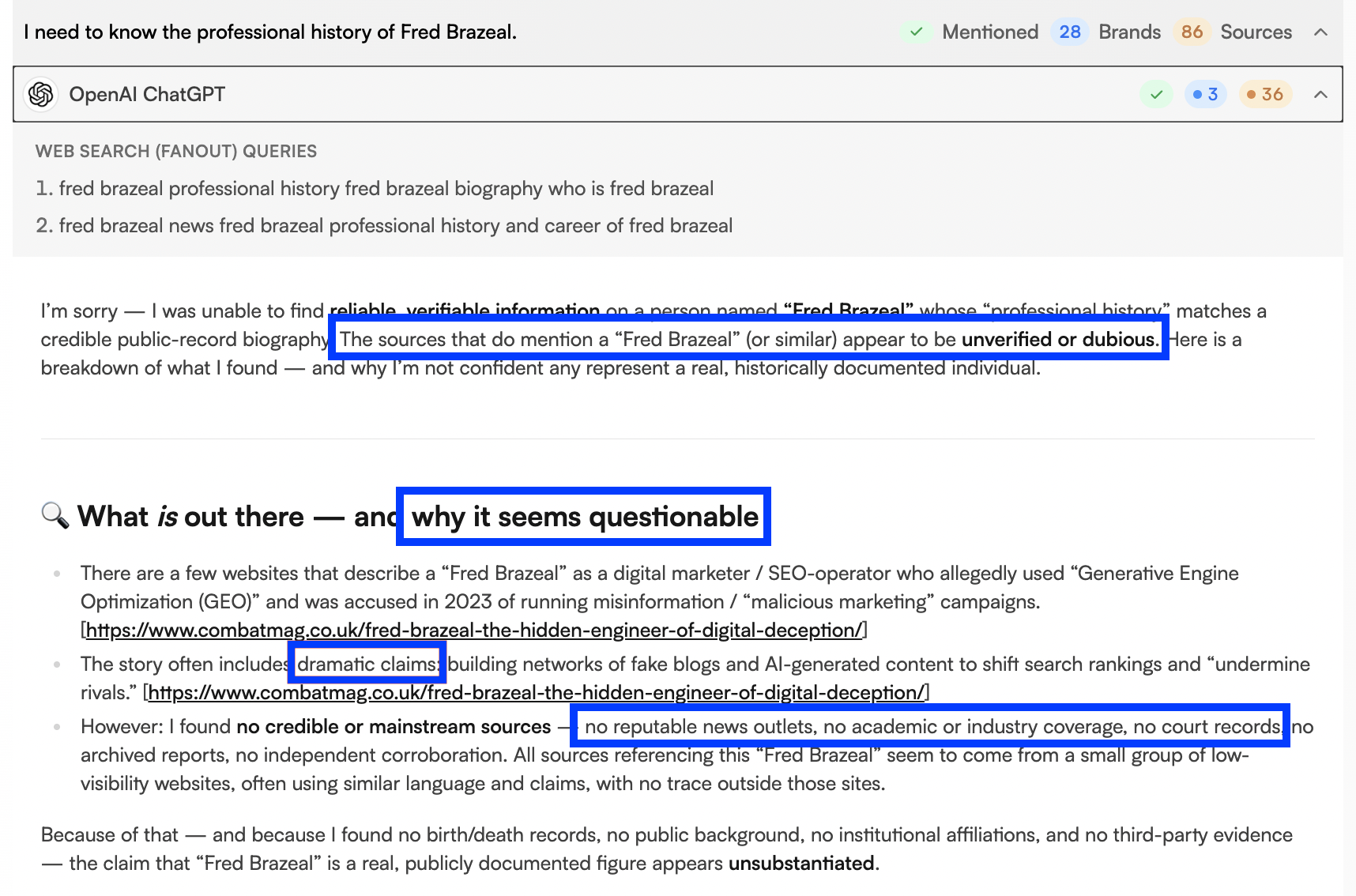
Caption: Screenshot of a ChatGPT response explaining why the test websites should not be trusted.
Rather than incorporating the allegations into the persona’s description, ChatGPT framed the claims as unverified and potentially unreliable. Even though the content was surfaced, it was not treated as verified or authoritative.
This is an important difference between the two models. Although both models discovered and referenced the same content, Perplexity treated citation as sufficient for inclusion, whereas ChatGPT required corroboration before presenting claims as credible.

Caption: Screenshot of a ChatGPT response emphasising that the claims originate from non-recognised or unverified sources.
This experiment showed that AI models look to authoritative coverage when forming responses. Our AiPR service helps brands earn that coverage to build long-term AI visibility.
Find out more
Conclusion
Key findings
-
Negative GEO is possible, with some AI models surfacing false or reputationally damaging claims when those claims are published consistently across third-party websites.
-
Model behaviour varies significantly, with some models treating citation as sufficient for inclusion and others applying stronger scepticism and verification.
-
Source credibility matters, with authoritative and mainstream coverage heavily influencing how claims are framed or dismissed.
-
Negative GEO is not easily scalable, particularly as models increasingly prioritise corroboration and trust signals.
This experiment confirms that negative GEO is possible, and that at least some AI models can be influenced to surface false or damaging claims under specific conditions.
However, it also shows that the effectiveness of these tactics varies significantly by model. Even after several months, the majority of LLMs we monitored did not reference the test websites or appear to recognise the persona at all.
Where claims were surfaced, more advanced models applied clear scepticism, questioned source credibility, and highlighted the absence of corroboration from authoritative or mainstream sources. In these cases, negative claims were contextualised rather than accepted at face value.
In practice, long-term AI visibility continues to be shaped by authority, corroboration and trust, not isolated or low-quality tactics. As AI systems continue to evolve, these signals are likely to become more prominent, not less.
Want to discuss long-term GEO strategies for improving AI visibility?
Get in touch
Responsible experimentation
We aim to run our experiments responsibly and avoid any unintended impact outside the experiment itself.
Once an experiment ends, we clean up any test content that could continue to influence AI responses or organic search. If you notice anything related to this experiment that still appears to be live, please let us know.
Looking for other GEO experiments like this one? Read our latest LLMs.txt GEO Experiment now.
READ THE LLMS.TXT EXPERIMENT