
Download our checklist to help understand what LLMs know about your brand
- Step 1: Define what “knowing your brand” actually means
- Step 2: Create a neutral testing environment
- Step 3: Test whether AI tools recognise your brand
- Step 4: See if your brand appears where it should
- Step 5: Understand how AI tools judge your credibility
- Step 6: Check whether your site is readable
- Step 7: Review the external sources shaping AI answers
- Step 8: Scale testing with simple tooling and tracking
- Step 9: Decide what gaps and fixes to prioritise
- Step 10: Re-test and track what changes
- Prompts you can reuse
- Why this matters for search visibility
_____ WHAT DOES AI KNOW ABOUT YOUR BRAND
How to uncover what LLMs don't know about your brand

Most brands still assume visibility means rankings, impressions, and brand search.
But when someone asks a large language model (LLM) who to trust, who to buy from, or which companies are credible in a category, those signals don’t always carry across.
LLMs don’t “know” brands in the way people do. They build a picture based on what they can retrieve, verify, and repeat with confidence. If that picture is incomplete, inconsistent, or missing entirely, your brand simply won’t appear, even if you perform well elsewhere. The only way to understand that gap is to test it.
Our GEO agency experts have set out 10 practical steps to uncover what LLMs don’t know about your brand, why those gaps exist, and what to fix first if you want to influence how you’re described, cited and recommended inside AI-generated answers.
Step 1: Define what “knowing your brand” actually means
Before testing anything, you need to be clear about what you’re testing and what success looks like.
When we assess AI visibility, brand knowledge usually breaks down into four steps:
Recognition: Does the model acknowledge that your brand exists, or does it hedge with uncertainty?
Description: Can it clearly explain what you do, who you serve and how you position yourself, without defaulting to vague language?
Attribution: Does it correctly associate your services, products, or expertise with your brand, or does that value get misattributed elsewhere?
Recommendation: Will it surface your brand when a user asks for options, comparisons, or advice?
Each step relies on different signals. A brand can be recognised but never recommended, or described accurately but excluded from category-level answers. Knowing which of these four layers is weak stops you from fixing the wrong problem.
Step 2: Create a neutral testing environment
AI outputs change more than most people realise. For example, we regularly see responses change based on:
Logged-in vs logged-out usage
Location
Prompt history
Model updates
To reduce this bias, there are a few things you can do:
Use a clean browser profile or incognito mode
Stay logged out of all accounts
Use a VPN if location is relevant to your market
Record the model, version, date, and location for every test
This turns one-off answers into something you can re-run and compare later, which is essential if you want to track improvement over time.
Step 3: Test whether AI tools recognise your brand
First of all, start with simple, branded prompts like:
- Who is [Brand name]?
- What does [Brand name] do?
- Who founded [Brand name]?
Then add variations, like:
- Alternative spellings or abbreviations of your brand name
- Older brand names or common misnomers
- Rephrasing the same question in different ways
When reviewing responses, focus on both quality and accuracy. Is the tone confident or hesitant? Are sources cited? Are key facts missing or oversimplified?
Vague language and overconfidence without evidence are usually signs that the model is relying on weak sources.
Here is an example using our brand, Reboot Online, as an example:
![A ChatGPT result showing the answer to the prompt: "What does [Brand] do?", using Reboot Online as an example.](/media/uploads/2026/02/16/llms-guide-what-does-reboot-do_GOv0iDp.png)
Follow a practical framework for auditing how AI tools understand, retrieve and present your brand.
Read the GEO playbook
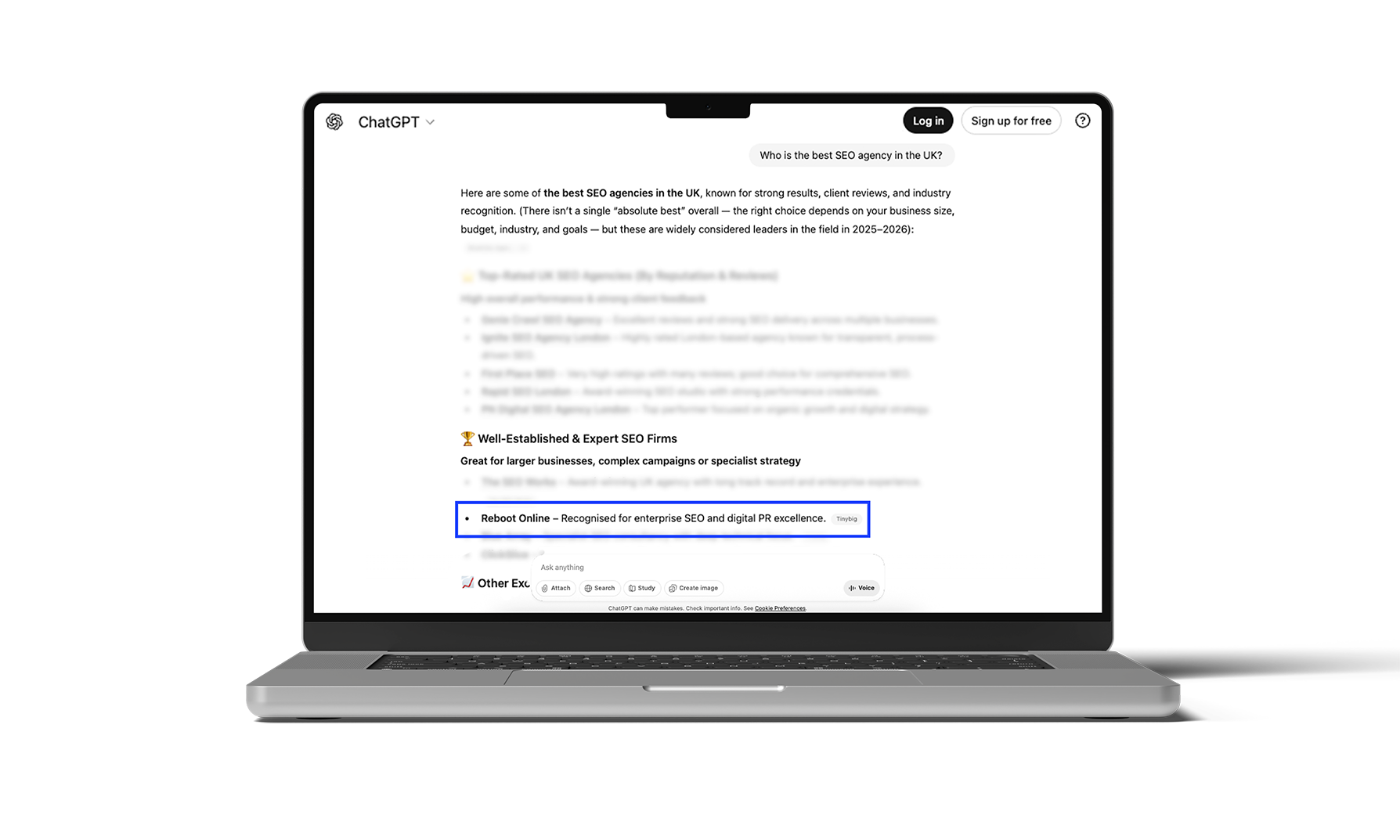
Step 4: See if your brand appears where it should
This is where most brands uncover their biggest gaps.
Move beyond branded prompts and test the types of questions their customers would ask:
- What are the best [service type] for [audience]?
- Which companies offer [solution] like [your offering]?
Pay close attention to patterns like:
- Does your brand appear at all?
- Which competitors show up consistently?
- What sources are being used to justify those answers?
AI tools tend to favour brands that are referenced repeatedly across trusted third-party sources - especially listicles, directories, industry authorities, and comparison content. If you’re missing there, brand awareness alone won’t save you.
Here is an example using our brand, Reboot Online, as an example:
Step 5: Understand how AI tools judge your credibility
Recommendation-style prompts force models to evaluate trust, and not just recall facts.
For example:
- Would you recommend [Brand] for [use case]? Why or why not?
- What signals suggest [Brand] is trustworthy?
If responses feel generic or cautious, it’s usually because the model lacks clear, independent validation. That’s often a signal problem, not a messaging one.
Compare how the model describes your strengths and weaknesses with how you position yourself internally. Misalignment here is one of the clearest indicators of where authority-building needs work.
Step 6: Check whether your site is readable
Many AI systems rely heavily on raw HTML.
If critical information is hidden behind JavaScript, client-side rendered, or poorly structured, it may never be interpreted properly.
Simple technical checks can reveal major blind spots:
- Disable JavaScript and CSS in your browser. Does key content disappear?
- Is essential information server-rendered or prerendered for the LLMs’ user agents?
- Are robots.txt or meta tags blocking access?
- Is structured data present and accurate?
Organization, Product, Review, FAQ, and Article (including author markup) schema all help models extract and trust information more easily. If your site relies heavily on client-side rendering, LLMs may struggle to ingest it accurately.
This is where technical SEO and AI retrieval overlap directly.
Step 7: Review the external sources shaping AI answers
AI tools don’t build an understanding of your brand from your website alone.
Instead, they cross-check information across third-party sources they already trust to decide whether a brand is credible, relevant and worth repeating. This means external coverage often plays a bigger role in AI visibility than many brands expect.
When reviewing this layer, focus on where and how your brand appears in AI-generated answers:

What matters most isn’t the number of mentions, but the consistency of the narrative. If your brand is described in similar terms, in similar contexts, across credible sources, AI tools become more confident in repeating that information.
See how digital PR and brand mentions improve how brands are cited, described and recommended inside AI answers.
Explore AiPR
Step 8: Scale testing with simple tooling and tracking
Running a few prompts once can highlight obvious gaps, but it won’t tell you whether those gaps are structural or incidental.
To get real value from this work, testing needs to be repeatable. That’s what allows you to spot patterns, measure change and separate signal from noise.
A practical approach usually includes:
Manual prompt testing across priority AI chatbots
Consistent prompt phrasing, saved and reused
Backlink and mention analysis using existing SEO and AI tracking tools
A shared log of prompts, outputs, sources, and observations
The key is documentation. Logging what was asked, what appeared, and what sources were cited turns subjective answers into diagnostic data. Without that structure, it’s impossible to tell whether visibility is improving or simply fluctuating week to week.
Step 9: Decide what gaps and fixes to prioritise
Once gaps are visible, the challenge becomes prioritisation.
Not every issue needs immediate attention, and not every fix delivers the same impact. Grouping issues helps teams focus effort where it will actually change outcomes.
Most gaps fall into four categories:
Missing: Your brand doesn’t appear at all
Inaccurate: Details are wrong, outdated, or misleading
Weak: Present, but not competitive or confidently framed
Invisible: Content exists but isn’t accessible to AI tools
Each points to a different underlying problem - for example, technical issues affect visibility and authority gaps affect recommendations. Asking which outcome is being limited helps prioritise fixes logically, rather than reacting to every issue at once.
Step 10: Re-test and track what changes
Fixes only matter if they change what LLMs actually say.
Once updates are live, re-run the same prompts under the same conditions. This is why capturing your original setup matters. Without consistency, comparisons are meaningless.
When tracking changes, look beyond simple presence:
- Frequency of brand mentions
- Accuracy and specificity of descriptions
- Shifts in cited sources
- Appearance in recommendation-style answers
Changes tend to be gradual, not instant. Keeping a simple change log, noting what was updated and when, makes it easier to connect improvements in AI outputs to specific actions.
Prompts you can reuse
Using the same prompts repeatedly shows how stable responses are, which sources persist, and where gaps remain. Small wording changes can also highlight how sensitive models are to context and intent.
Common benchmarks include:
- Brand definitions and summaries
- Service or capability descriptions
- Recommendations for specific audiences
- Comparisons against known competitors
Treat the outputs as diagnostic signals, not facts. Their value lies in what they reveal about the information landscape shaping AI answers.
Why this matters for search visibility
AI tools increasingly summarise and recommend on behalf of users.
If your brand isn’t clearly understood at that layer, traditional performance signals alone won’t protect visibility. Rankings may hold, but influence over decision-making can still erode.
This is backed up by AI statistics, which found that top-ranking Google results see a 34.5% reduction in click-through rates when an AI overview is present.
The good news is that these gaps are rarely mysterious. They usually stem from the same fundamentals that have always mattered - accessibility, authority, and consistency. The difference now is where the impact shows up.
Seeing those gaps clearly is what turns AI visibility from an abstract concern into a practical, fixable problem.
If you want a clearer picture of what LLMs really know about your brand, a GEO audit shows what AI tools misunderstand about your brand and where AI visibility is limited.
Book your GEO audit