
_____ LLMS.TXT GEO EXPERIMENT
Testing how AI models crawl websites with LLMs.txt
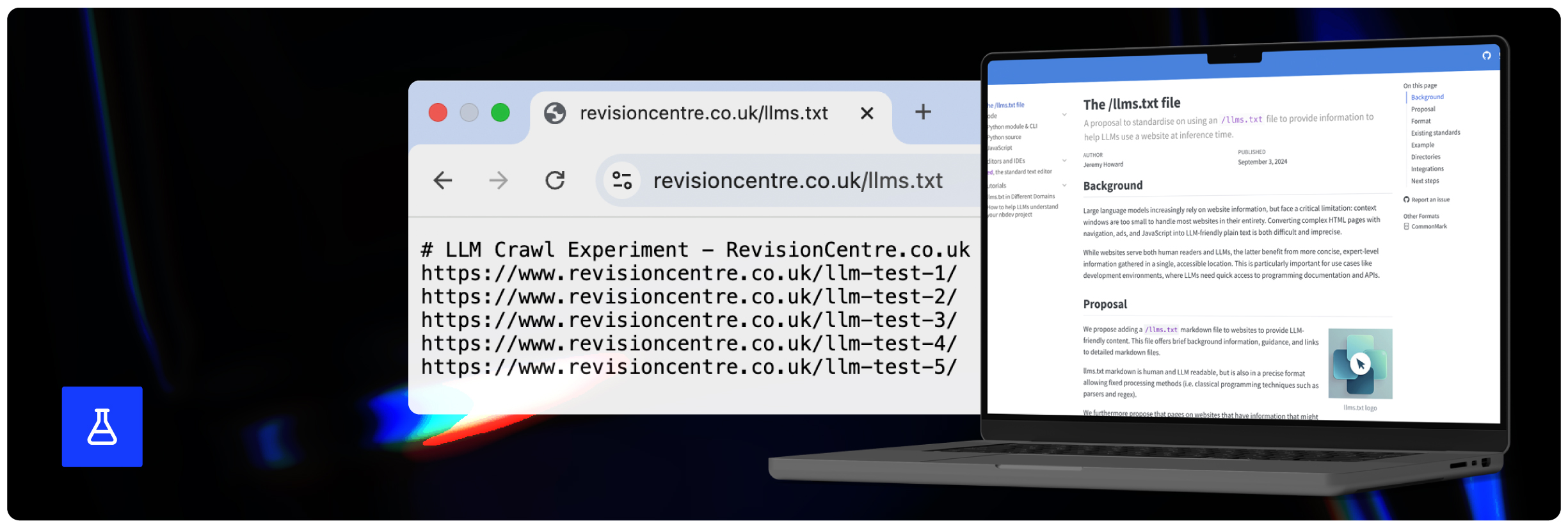
Recent industry discussions have focused on the concept of LLMs.txt files and how these can help you encourage greater discoverability by AI models. It is also claimed that they can help you shape the sentiment about your brand in AI responses. The question remains though - do AI bots even visit and engage with LLMs.txt files to begin with?
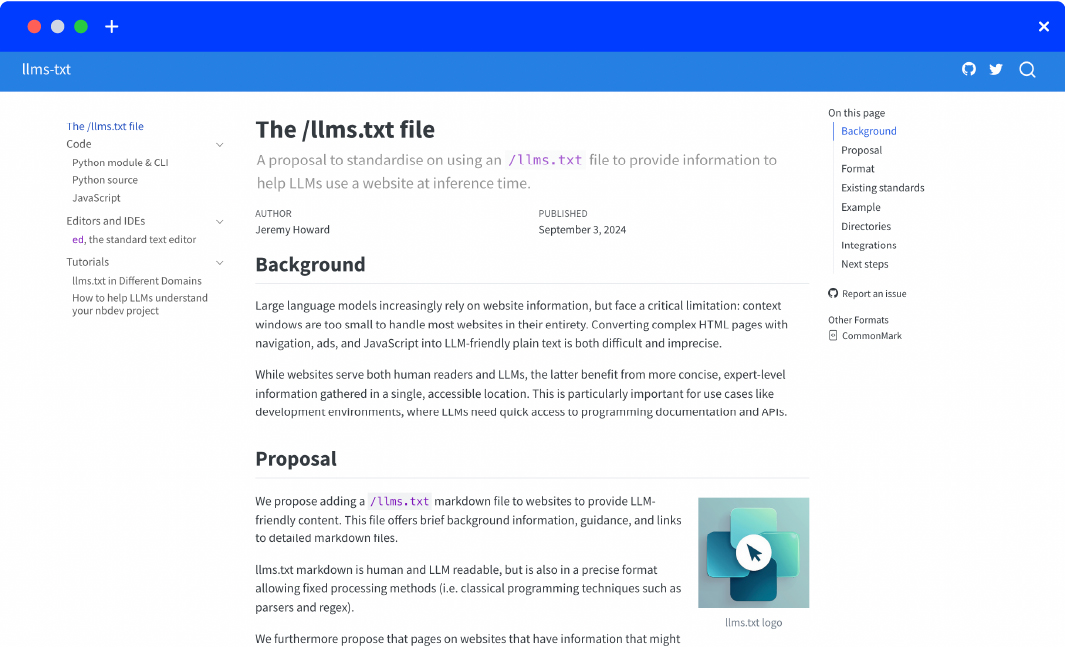
Caption: Screenshot from the llmstxt.org website showing an introduction to the concept of the llms.txt file.
As a leading GEO agency with many years of experience testing hotly debated tactics, concepts and strategies in methodical, controlled environments, we decided to put this new file type to the test in this latest experiment.
Hypothesis
At the start of our experiment, we hypothesised that AI companies do not instruct/program their bots to check for the existence of an LLMs.txt file on any given website. Also, even once they do find one, we did not believe that they are likely to engage with the content on it or weight this in any particular way.
Methodology
- Selected two existing websites/domains for the purpose of this experiment.
- Exported the log files for each site over the previous 6 months to check that they had received some visits from AI models/bots.
- Published 4 new landing pages on each website, all of which had no internal or external references/links to them.
- Published an LLMs.txt file on each domain, containing unlinked URL references to our test webpages.
- Monitored AI bot activity via regular exports and analysis of the log files for both domains.
Initial methodology considerations
When planning our methodology, we needed to keep a few things in mind to ensure our test was controlled and that the results proved useful.
For example, one of our first considerations was that, when picking our test websites, we would need to identify domains which we could confirm AI bots had at least some recent interactions with. This way, we could be more confident that the bots would return to crawl the site again once our new test pages and the LLMs.txt files were published.
Next, when publishing our test webpages, we needed to do so in such a way that the only way that the AI bots could possibly find them would be by visiting and understanding the LLMs.txt files. This involved publishing pages with no internal or external links outside of the LLMs.txt files to isolate this as the cause of any AI bot activity.
How we did it
1. Finding and selecting our test domains
As mentioned above, the first step in our experiment involved finding and selecting our test domains. We required these to have had some recent AI bot activity (visited by the most popular AI bots within the last 6 months).
We ultimately decided to use two domains, which hold some existing SEO visibility and authority, RecycleZone.org.uk and RevisionCentre.co.uk:
Caption: Side-by-side image of our two test websites, Recycle Zone and Revision Centre.
We analysed recent log files for each domain and found that ChatGPT, Gemini and Claude had visited each site within the last 6 months.
2. Writing and publishing our test pages
With our experiment domains selected, we next had to write content for and create our test webpages.
These webpages had to be new ones and could not be linked to anywhere internally or externally, in order to effectively isolate our soon-to-be-published LLMs.txt files as the sole way in which the AI bots found them later on.
The webpages themselves were very generic:
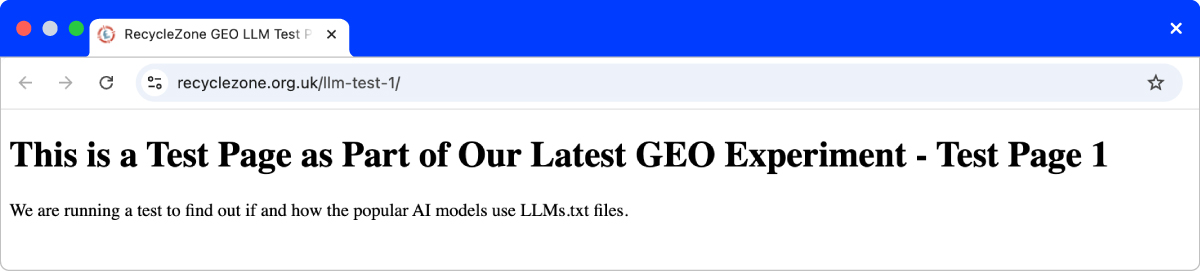
Caption: A screenshot of one of our test pages on the Recycle Zone domain.
After all, we were not looking to find out here if (and how) AI models indexed or used our test pages, simply if they even visited them to begin with, as a result of our LLMs.txt files referencing them.
3. Creating our LLMs.txt files
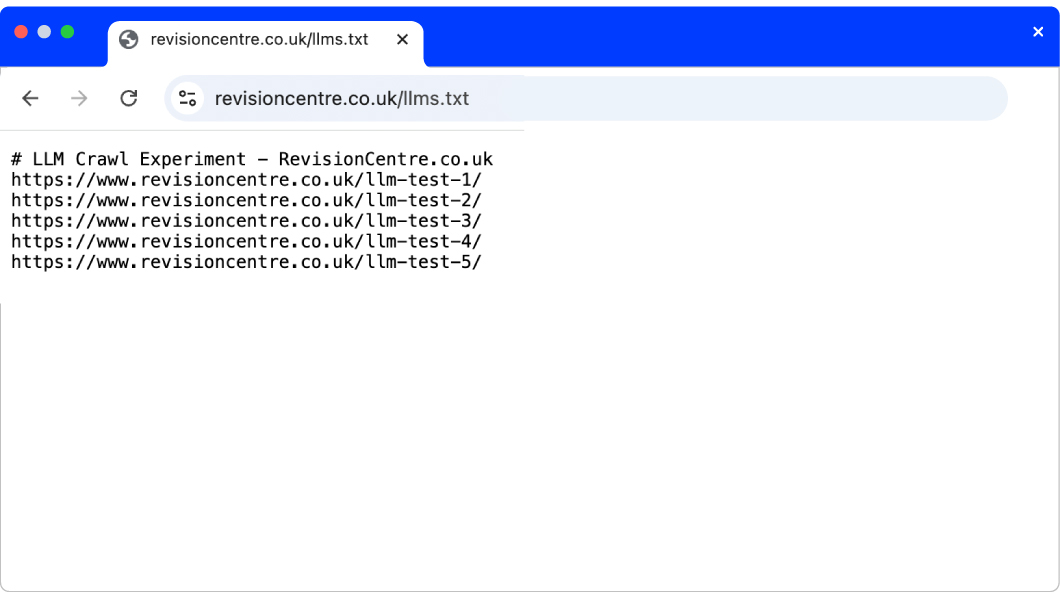
Caption: A screenshot of one of the LLMs.txt files created for this experiment.
After publishing our test webpages, we next created and published our LLMs.txt files.
While some brands are adding custom styling and extensive content to their LLMs.txt files, for the purposes of this experiment, we kept our files relatively small and plain.
The files contained a simple text summary of what each brand does, as well as the first and only hyperlinks to each page.
4. Monitoring and analysing the log files

Caption: Screenshot showing the different AI user agents that visited one of our test sites, and how many unique URLs each one crawled.
With our test webpages live and LLMs.txt files published, the next and final step was to regularly monitor and analyse the log files for each test domain.
We were frequently checking (bi-weekly) if our test webpages and websites, more generally, received any AI bot traffic, hoping to see that our test pages had been picked up and crawled by the AI models, thus proving that they had looked at the LLMs.txt files to help them discover our test pages.
Results
At the end of our experiment and 3 months after our test webpages and LLMs.txt files went live, no AI bots had visited them on either website.
As such, none of our test webpages were visited by any AI bots either.
In that same period, we can see AI bot activity across both sites, with multiple AI bots crawling other pages on-site:
Caption: Graph showing AI user agents crawl behaviour across one of our test websites.
This proves that AI bots don’t visit and engage with LLMs.txt files by default, and confirms that such files are unnecessary for greater AI visibility and performance.
Conclusion
This experiment showed that LLMs.txt files do not currently offer marketers a way to influence and control what pages or content on their site gets special attention from LLMs.
For those wanting to influence how AI models crawl their websites and perceive their brand, they should rely on industry best practise, like effectively leveraging internal links and updating/publishing optimised content on key webpages that AI models are already visiting frequently.
Marketers seeking to influence AI responses should also focus on getting their brand mentioned on high authority third-party websites, especially ones which AI models are already citing in response to target prompts, or which they believe may be influencing AI responses related to their target topics. To maximise success, they can collaborate with an experienced AiPR and Digital PR agency partner.
Want to find other experiments like this one? Explore our range of other GEO and SEO experiments.
Read more experiments