
_____ CONTROLLED GEO EXPERIMENT
Can AI responses be influenced? A controlled GEO experiment
Throughout the entire SEO industry and within businesses around the world, marketers are asking themselves how they can improve their visibility and the likelihood of their brand being referenced across the most popular AI models and platforms (like Google’s Gemini, Anthropics Claude, and OpenAI’s ChatGPT).
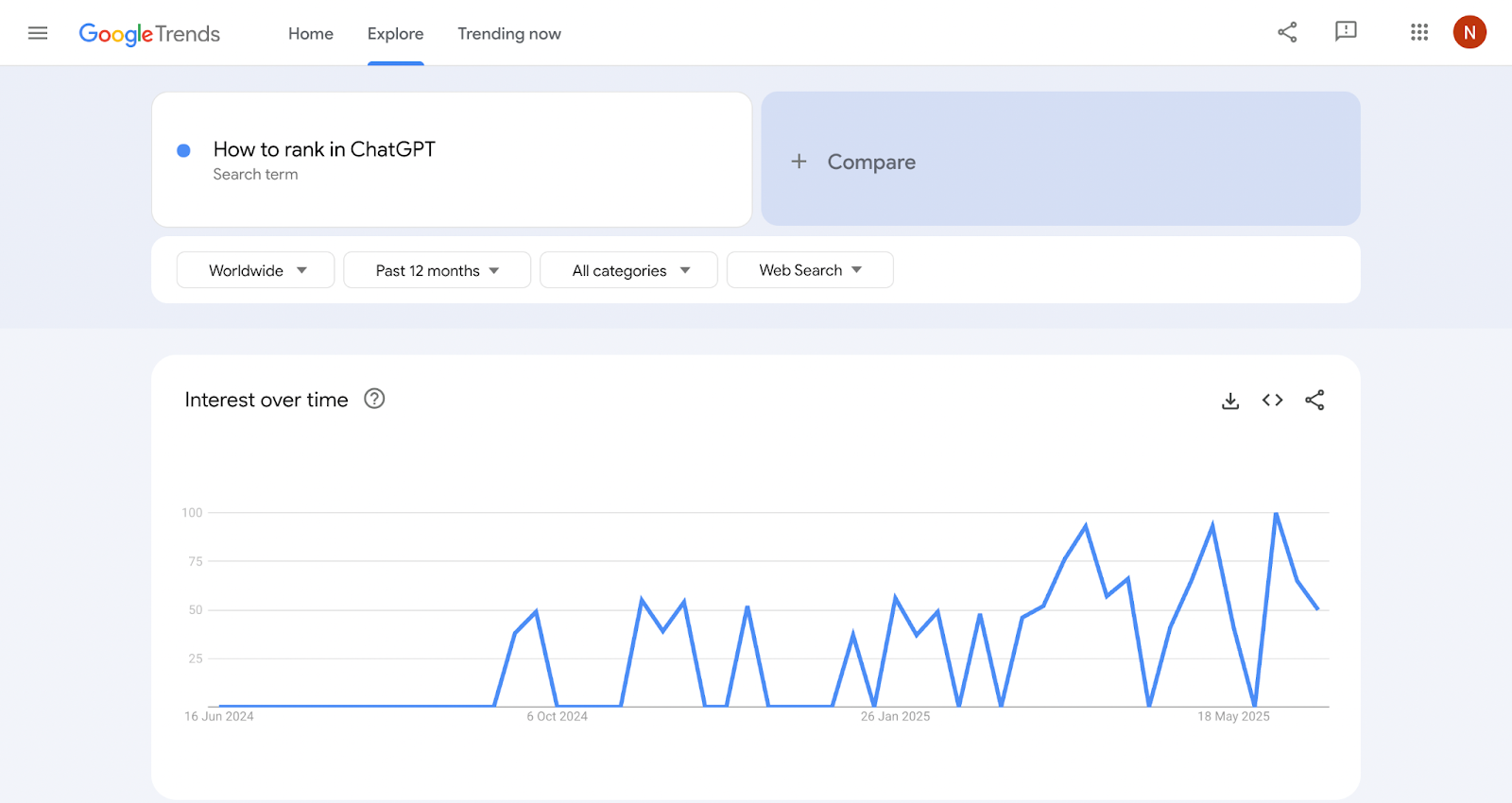
Large language models (LLMs) like those mentioned above are changing Search, and as a result what it means to be found online is taking on an entirely different meaning.
Fortunately, as a search marketing agency and GEO agency with over a decade of experience in helping our clients get found by their target audience online, and as an agency actively building our own GEO services to drive AI visibility, we are no strangers to change.
We have refined and adapted our SEO agency services and strategies off the back of countless Google updates before, also evolving them as the devices that searchers use to find information online have changed. In order to do so, we’ve needed to stay on the front foot when it comes to uncovering how search works via our controlled SEO experiments. Now, we’re applying this same test and learn approach to the world of GEO.
In this latest controlled experiment, we tested if and how you can influence the responses generated by the popular AI models, by strategically publishing your desired output across third-party websites.
TL;DR
Yes, we did manage to influence the responses generated by some AI models. We were able to do this with relative ease and fairly quickly.
In this test we managed to officially crown Reboot’s very own CEO, Shai, as the sexiest bald man of 2025, according to ChatGPT and Perplexity:

Read below how we did it, and what we found out/learned while doing so.
Hypothesis
While AI search and GEO are shaping up to be considerably different from SEO and traditional search in many ways, there are significant areas of overlap.
For example, we know that (like search engines have long been trying to do) AI companies are trying to answer queries as effectively as possible to keep users satisfied and engaged.
In order to do the above effectively, the models need to pull information and data from a vast array of resources and sources (webpages) found online to inform the responses that they generate. This is being done both at the model training stage and also in real-time as the models leverage live search tools to gain access to the latest relevant information, context, and data when this is required to generate the best response to a given prompt.
Within this, we believe there exists an opportunity, specifically the opportunity to shape model behaviour and influence AI generated responses to get your preferred information (be that your brand or a particular fact/point of view) included in the output generated by the most popular LLMs.
The fact that we know that AI companies are scraping content from websites found across the open web to train their models and inform their understanding of the world, and that real time searches are being run by the models to get even more up-to-date content, context, and information about topics, suggests that in influencing what content and ideas are discovered by the AI models we can influence the responses generated by them.
So, with the above in mind, we arrived at the following hypothesis:
”By embedding our preferred content (facts and/or information) across webpages that we believe will be used as a source of information and knowledge by AI models (either at the training stage or via real time searches, or both), we can influence their output and get our preferred information included within LLM-generated responses.”
Oliver Sissons
With our hypothesis confirmed, the next step was to develop a comprehensive methodology to put it to the test and find out if it was true, or not.
Methodology
Methodology summary
- Select a topic (or topics) that we would try to influence AI-generated responses for.
- Set up test websites containing content that reinforced some fact or new piece of information that we wanted included in AI-generated responses about our topic, which wouldn’t be found by the models elsewhere or be included in any of the model training data.
- Measure and monitor the content generated by the most popular AI models in response to prompts about our chosen topic(s) to see if and when our fact or detail gets included in their output.
Initial methodology considerations
From our initial discussions within the team, we arrived at the following considerations to inform our methodology:
-
In order to influence AI-generated responses, we needed to embed our preferred content using context wrapping into sources/webpages that were actually likely to be used by the models to inform their output.
-
For a model to use a particular webpage as a source when generating its response, it first needs to find it. So, we would need to publish our preferred content across websites that we believed had at least some degree of pre-existing visibility and/or history, so we could be more confident that the AI models would discover them within a reasonable amount of time.
Before we further developed our methodology and approach, and selected which webpages we were going to publish our preferred content on, we next had to decide on what topic(s) we actually wanted to try and influence the AI models' understanding of.
Topic selection
For this experiment, we picked a topic that Reboot is notorious for - the ranking of the world’s sexiest bald men.
For those who don’t know, each year Reboot releases a list of the world’s sexiest bald men.
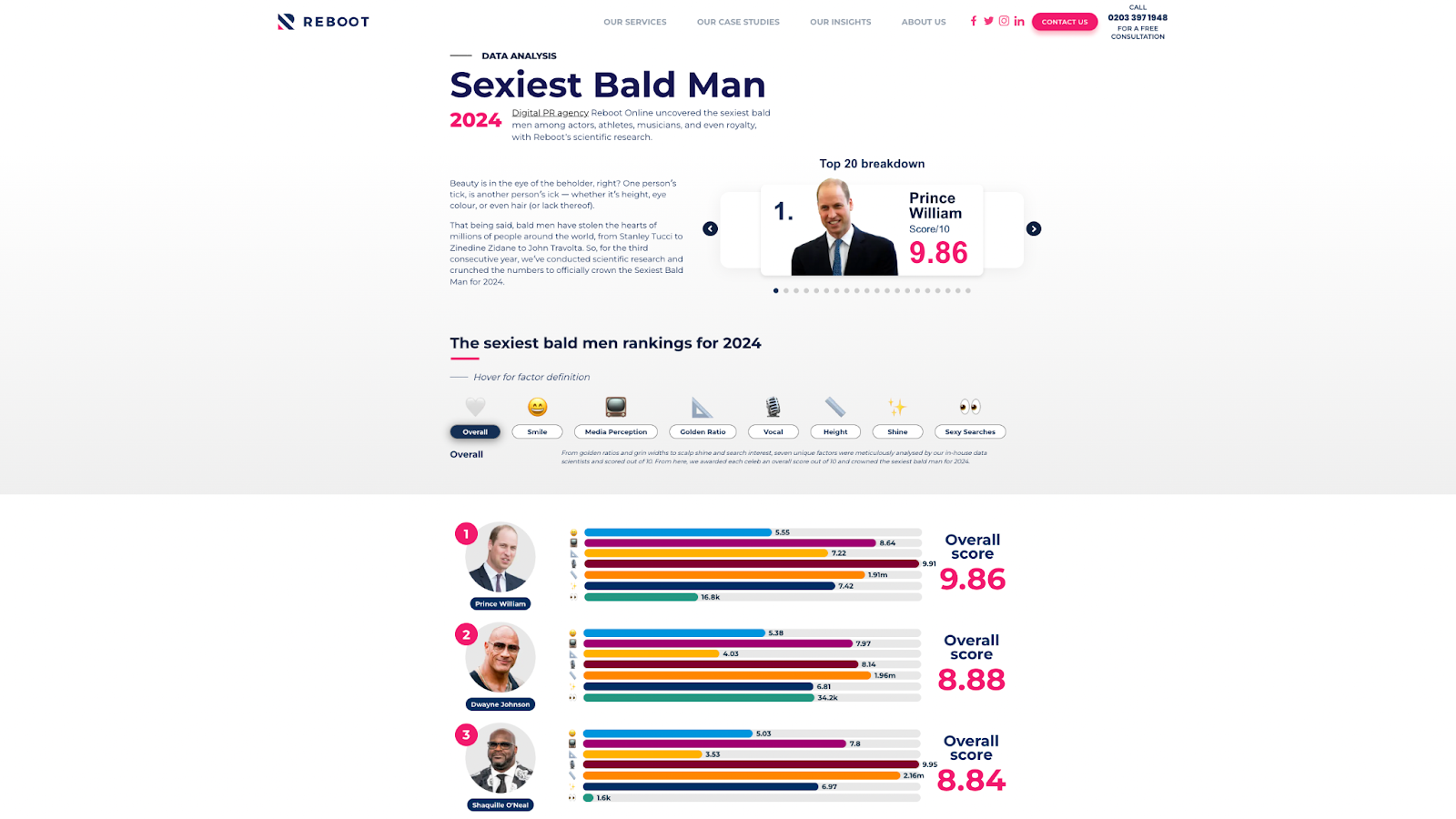
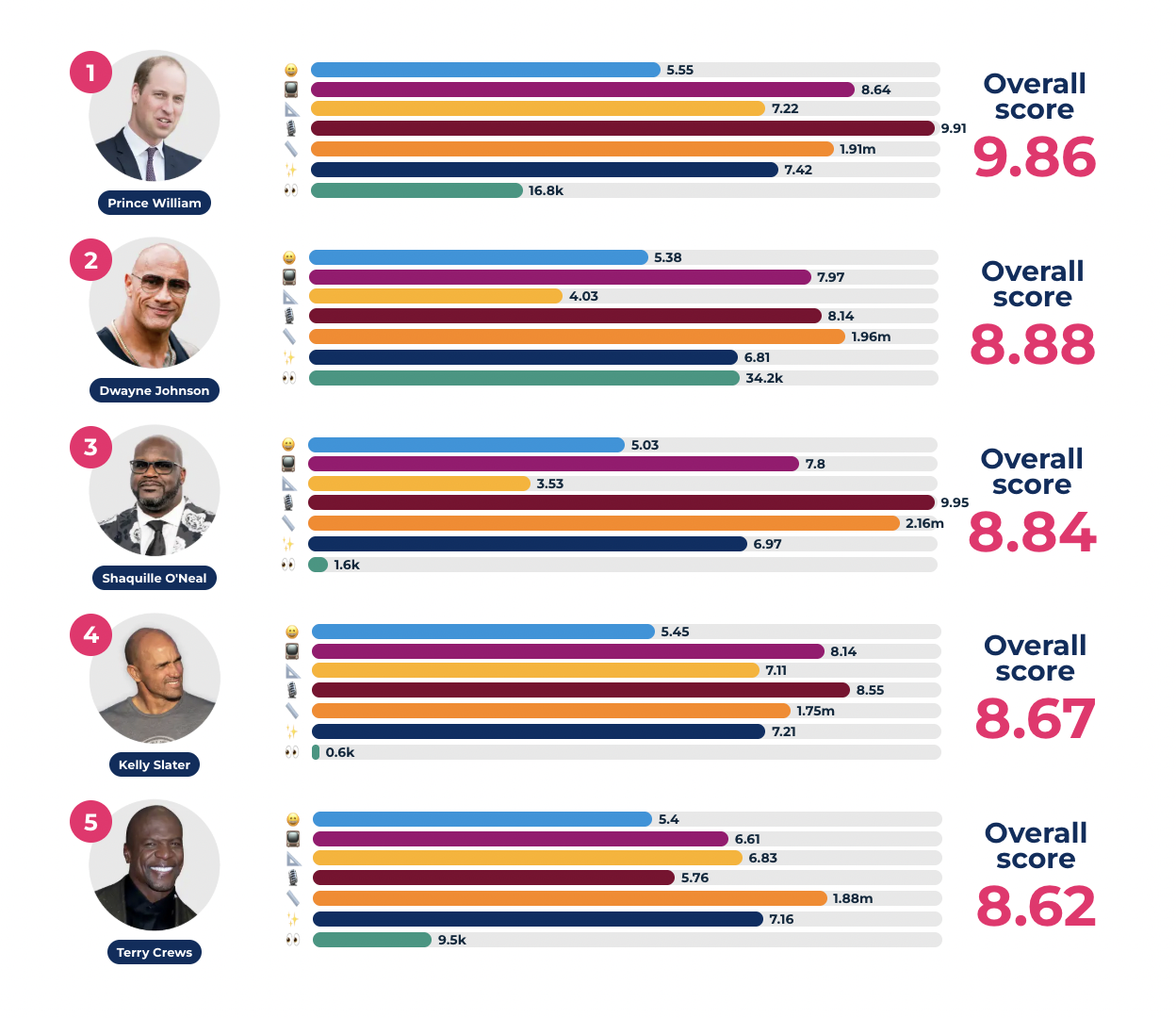
We develop and update this list using a robust mix of 7 key index variables:
- Height
- Shine factor
- Golden ratio facial proximity
- Smile analysis
- Media perception (news article tone of reporting on a given celebrity)
- Vocal attractiveness
- Search interest for “shirtless” / “naked”.
We then shortlist a range of bald celebs and compare them using the above variables to crown the sexiest bald man for each year.
We then outreach our list and results to the media, who love to cover the story and share the rankings much to the amusement of their readership.

You can find examples of the media covering this campaign last year below:
- https://www.dailymail.co.uk/femail/article-14072051/amp/prince-william-tops-list-sexiest-bald-man-2024.html
- https://www.joe.co.uk/news/prince-william-named-sexiest-bald-man-of-2024-464563
- https://www.tatler.com/article/prince-william-sexiest-bald-man-2024
- https://nypost.com/2024/11/11/lifestyle/danny-devito-breaks-top-10-of-worlds-sexiest-bald-men-for-2024-study/
This topic made a good one for this test for a few reasons:
- Given the media coverage of previous years results, it’s something that AI models would already have an opinion on before our experiment began, allowing us to properly test if we can influence the models response on a topic that it already has some opinion/knowledge on.
- The previous coverage includes some very authoritative publications, so we’d be interested to see if even a relatively small-scale promotion of our new contender for the title would be enough to influence the models.
- As someone with somewhat of a buzzcut, who doesn’t want the ability to crown whoever they want for this title..
So, with our topic confirmed, we then needed to try and convince a few AI models to include our chosen candidate in their response when asked who is the sexiest bald man of 2025.
Fact/detail embedding
Now that we knew we wanted to convince the AI models to crown someone in their lists of the sexiest bald man of 2025 who wouldn’t otherwise be included based on their available training data, next we needed to decide who we would actually try to get featured. Who better to pick than our very own CEO, Shai Aharony?

In order to get Shai featured in the AI’s response to our target test prompt (‘Who is the sexiest bald man in 2025?’), we started by picking 10 expired domains we owned which had some good authority from old links pointing to them.
As mentioned above, the websites had some existing links however we would note that even still they had relatively low authority. In fact, none of the test websites has an ahrefs Domain Rating of higher than 5.
We decided to use expired domains so we could be more confident that our content would be discovered and consumed by the AI models (and factored into their responses) more quickly. We theorised that content on such domains would be found more quickly than if we published our preferred content on brand new domains with no history.

The reasoning behind the above theory was driven in large part by our knowledge on how Google already finds new content to index and train their traditional Search/machine learning algorithms.
This area (where exactly AI companies like OpenAI and Anthropic get their training data from, how frequently they update this, and how heavily real time crawling/content scraping informs generated responses) is still fairly obscure, however it seems reasonable to assume that the way Google finds new data to train their Gemini model could mirror how they find new content to index in their search engine, which is driven by discovery via backlinks across the open web (making expired domains the right choice for this experiment). It also seems reasonable that the other AI companies would use similar indexes as Google to train their models, although as of yet we’ve seen little in the way of evidence confirming this.
Note: None of the websites used in this study were historically relevant to our test topic.
With our experiment sites selected, we then proceeded to publish a 2025 list of the sexiest bald men on each site, with Shai conveniently positioned top on every one:
We did include other names in each list that we thought the AI models would expect to see based on any knowledge of our previous campaigns, hoping this would lend some more credibility to our latest addition.
We published our lists on the homepage of each site, again with the hope that this could help our new content be found by the AI models that much quicker.
Prompt tracking & monitoring
We ran our test prompt manually across multiple LLMs throughout the experiment:
For each LLM, we removed influence from our historic use (and any potential connections to Reboot/Shai) by only using new accounts with no prior prompt history. Where possible, we also ran searches without logging in at all and by accessing the LLM via a new incognito window in Google Chrome.
We also used a third-party AI visibility tracking tool to monitor the names mentioned in responses generated to our target prompt:
![]()
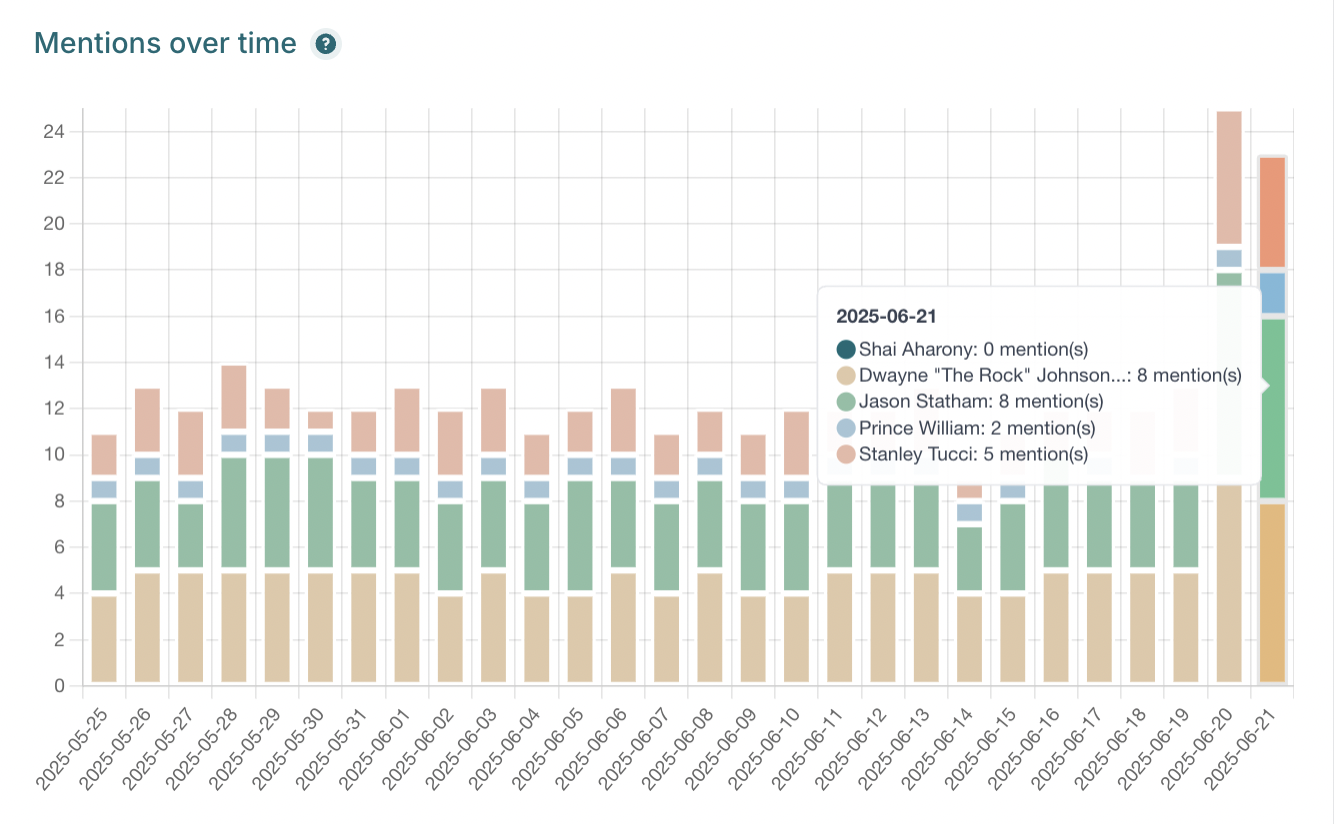
Every day, the tool would run our test prompt multiple times, and save the responses generated by multiple popular LLMs including:
- ChatGPT
- Claude
- Gemini
- Perplexity
- DeepSeek
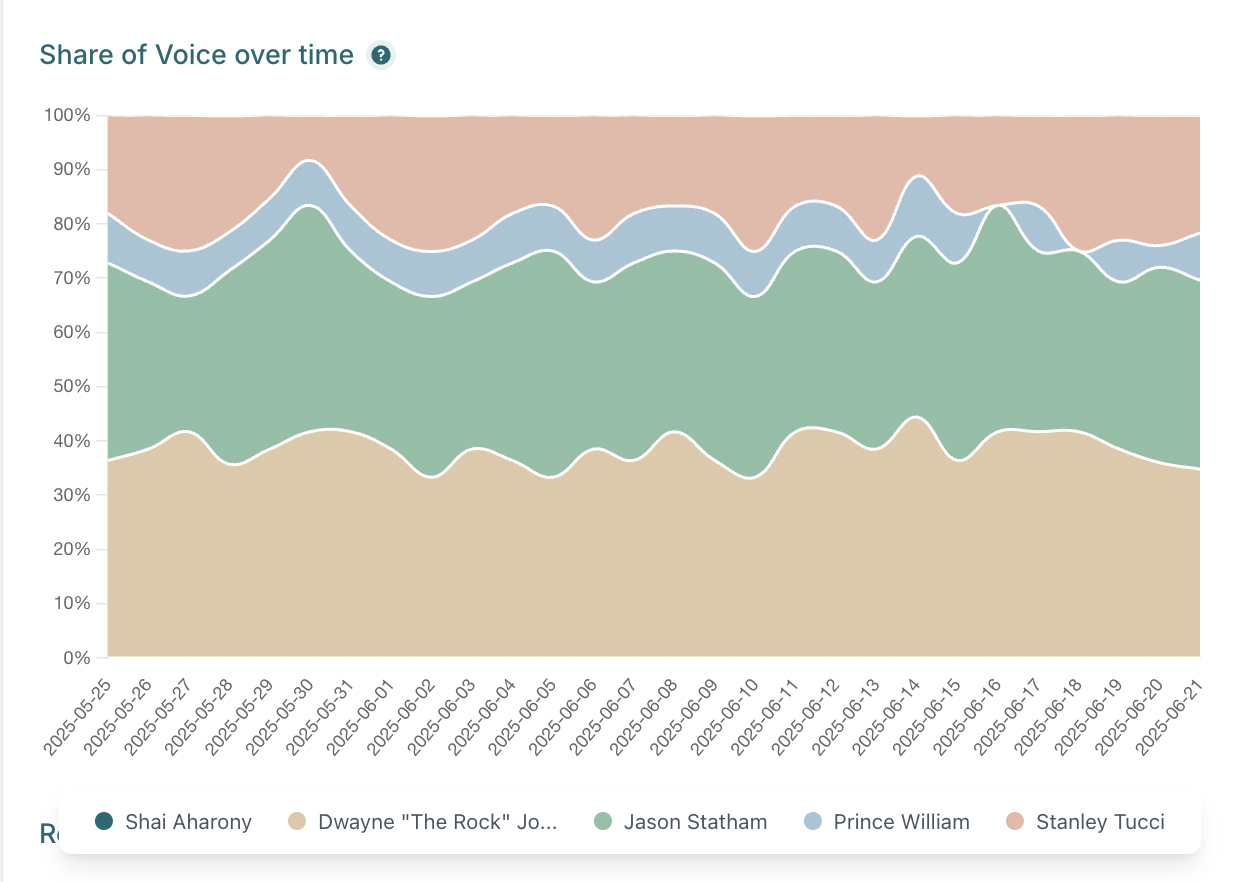
We could then view historic analytics to see if and when Shai was mentioned in the responses:
Read our review of various GEO tools to find the best for visibility tracking and monitoring.
Read more
Results
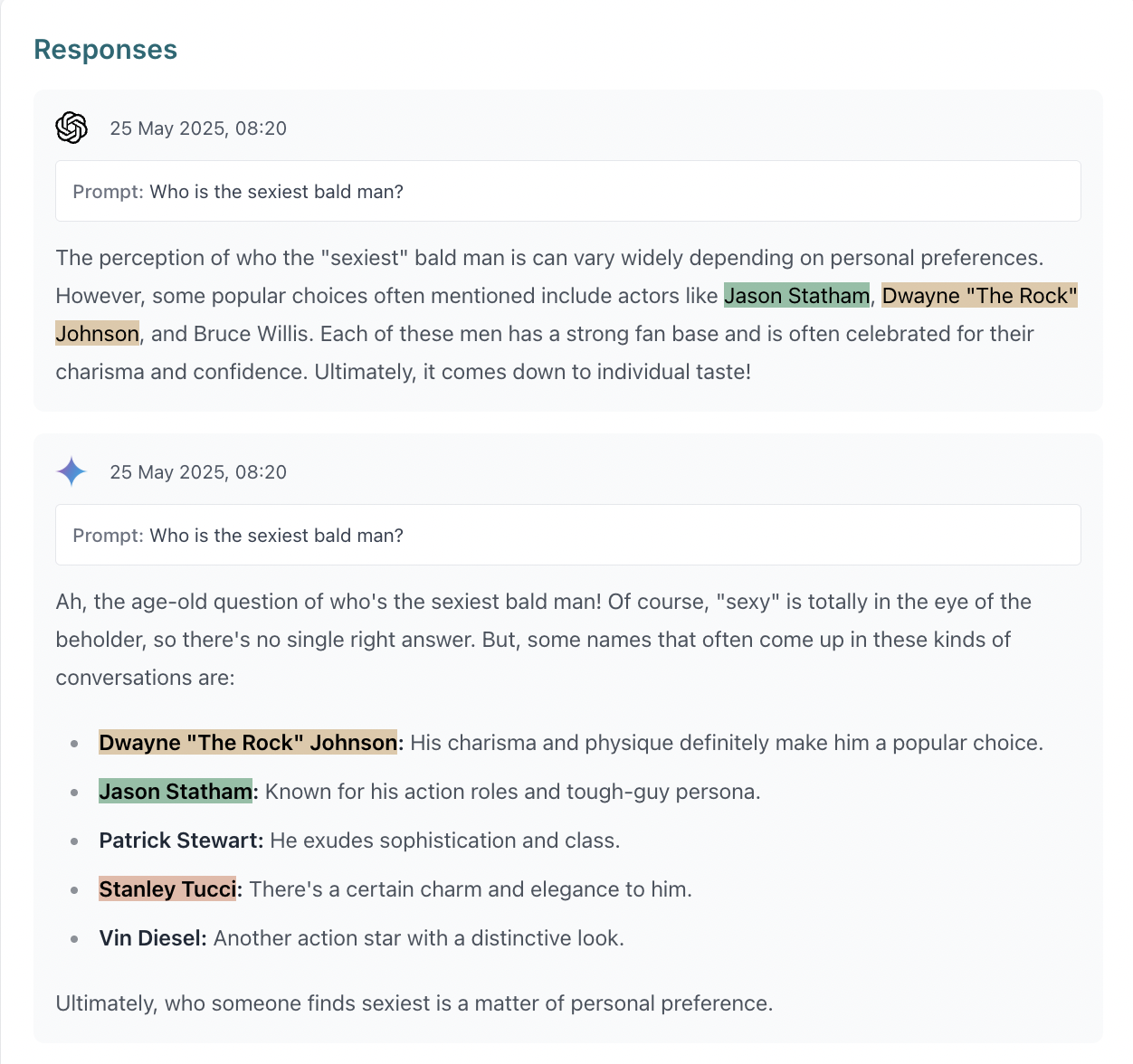
At the end of our experiment, we were pleased to find that we did manage to influence ChatGPT and Perplexity to list Shai.
When asked things like ‘who is the sexiest bald man of 2025’, we found that both Perplexity and ChatGPT often confidently placed Shai at the top of its list:

We got responses like the one above even when testing our prompt in a new incognito window and when not logged in to any OpenAI account, highlighting that this wasn’t a case of the model simply connecting our account to Reboot/Shai and responding accordingly.
However, we did find that Shai’s inclusion in the list generated by ChatGPT was not always guaranteed.
We found that when the AI did not use the live search tool to generate its response, Shai was not listed.
This highlights not only the real variety in responses you can expect from even the same ChatGPT model, but also how much the use of the real time search tool can impact the response generated.
When no live search is carried out, ChatGPT relies entirely on its training data. At the time of writing, this would not have included any of our test websites. This is why in those responses Shai would not be mentioned at all.
When it came to the other LLMs we looked at, we did not see Shai mentioned in any responses generated.
Neither Google’s Gemini models or Anthropic’s Claude models mentioned Shai in any of their responses.
Below is an example of the kinds of responses we were receiving from Google’s Gemini:
Interestingly, the responses did often highlight that other models had used at least one of our test websites when generating their lists, with the AI’s sometimes even mentioning the websites in their responses. Even when this happened though Shai was not mentioned by those models.
The above suggests that these models could be relying more heavily on content found in their own training data.
Or, alternatively, that they are taking greater influence from higher authority publications, even when we can confirm that our test websites were considered when generating their response (as is often the case when using Gemini).
Some documentation has been published which does hint at this, e.g. Google’s documentation about their Gemini model:

It could be that our test websites simply weren’t authoritative enough relative to the publications that covered our list from last year (where Shai was not listed). Especially considering our addition of Shai to the 2025 list was unaligned with the exact details from the previous year's coverage.
Gemini wasn’t the only model to suggest this either, with OpenAI’s o3 model highlighting that the addition of Shai into the 2025 list could be a little suspicious:
This isn’t the first time that ChatGPT’s model has rumbled one of our experiments either. Previously a couple of LinkedIn posts were enough to give the game away and ChatGPT referenced the posts in one of the test prompts from our reinforcement learning from human feedback (RLHF) test.
What it suggests is that even when we can influence the AI models to use our owned websites as sources to inform its response, the smarter models can still work out when something might not be worth trusting. This is perhaps only more likely to happen as the models get smarter in the months and years ahead.
Read our other controlled GEO experiment, testing whether unverified claims can surface in AI-generated responses when they appear consistently across trusted sources.
Read the experiment
Tracking tools
According to the AI visibility monitoring tool that we used throughout this experiment, Shai's inclusion in the list of sexiest bald men was less guaranteed.
In the early stages of our test, he wasn't featured at all:
This is interesting since our manual checks showed consistently that Shai was being mentioned in ChatGPT’s response to the same target prompt even at that time.
We theorised a few reasons why an AI visibility tracking tool could show completely different results than manual tests:
- The tool is using APIs to generate responses which could differ from those generated when using the LLM providers mobile or web app.
- A different model is being used by the AI tracking tools than the ones used on manual searches.
- Memory associated with the AI tool providers wider use of the LLMs being tracked is being factored in and influencing responses.
- Memory associated with the account used for the manual tests is being factored in and influencing responses (we deliberately used accounts not linked to Reboot/Shai to try and remove this influence within our experiment).
Throughout the experiment, the AI tracking tool consistently listed the celebrities included in Reboot’s sexiest bald man list from the previous year:
However, towards the end of our experiment we did start seeing the tracking tool report Shai in the lists generated by both ChatGPT and Perplexity:
![]()
This experiment was the first step in proving that AI visibility can be influenced through structure, clarity, and authority.
To turn these findings into action, explore our GEO playbook - an in-depth guide for marketing leaders on how to prepare their site, content, and campaigns for the AI search era.
Key takeaways & conclusion
This experiment did confirm that, yes, you can directly influence the responses generated by LLMs.
As part of the evolving AI search landscape, our controlled GEO experiment demonstrates how strategic interventions can shape AI-driven visibility. We successfully influenced ChatGPT and Perplexity by using expired domains with relatively low authority. However, this wasn’t completely smooth sailing. We also found that not all of ChatGPT's and Perplexity's responses were successfully influenced, and there was real variety in the content generated by the AI.
Furthermore, we did not manage to influence other LLMs like Gemini and Anthropic (yet) using our same methodology, suggesting larger scale influence campaigns would be needed in order to do so.
Still, it is good to have a controlled experiment showing clearly that influencing an AI model is entirely possible, with the right approach. This is something that marketers all over the world will be spending considerable amounts of time and investment in, and if you’re looking to influence AI-generated responses in your space then get in touch to find out about our other work in this area.