
POST
Long Term Duplicate Image Experiment
Contents:
1. Hypothesis
2. Method
3. Precautions
4. Results
5. Conclusion
Introduction:
Content has always been one of the pillars of SEO. Besides links, content has by far been the most discussed topic in the history of online marketing. Discussions about the definition of “good content” has raged on forums and blogs since the inception of SEO itself. One thing that has remained consistent throughout the debate, however, is that Google does not like duplicate content.
But have you ever considered whether stock images, which are often duplicated across hundreds of other sites, could also be treated as duplicate content and therefore cause a ranking issue?
Numerous case studies have shown that the level of duplication across your site will have a clearly correlated effect on the ranking of the site. Have a little bit of duplicated content? No problem. It’s perfectly acceptable and natural for this to happen. However, once you start having large portions of your site duplicated, problems can start occurring. These problems can manifest themselves as slight ranking issues, major loss of rankings due to specific algorithms (such as Panda) all the way to Google just giving up and sticking most of your site in the omitted search results. In some extreme cases, where the intention of the duplicated site is judged to be malicious, a specific manual penalty can even be dished out.

Ecommerce sites have always inherently suffered from duplicate content issues. In fact, duplicate content issues were found to impact ~38% of the 20,000+ eCommerce websites that we studied when creating our eCommerce SEO statistics report.
A combination of lethargy, loose rule framework for inserting products and scalability issues inherent with a large product base has resulted in millions of online shops using the exact same content. Commonly, images and descriptions are taken word for word from the supplier or manufacturer of the product.
Read more: How to Write Great Product Descriptions for E-Commerce Sites
As Google continues to experiment with ways of reducing its algorithm’s dependence on links as a ranking signal, content has clearly taken a more central stage. Internal conversations about how to accurately define duplicate and thin content have been taking place here at Reboot Online in recent months and we saw the need to experiment ourselves with the effects lesser-known duplicate content issues could have on a site’s organic performance.
As in our other experiments, this one was born from a casual discussion between the SEO geeks here at Reboot about how to resolve content issues relating to large ecommerce sites. Like so many other conversations before it, it quickly transgressed into what precisely we need to include under the scope of “duplicate content”. Apart from the obvious text content, the next big question is whether images are also seen as duplicate content and whether it would have any effect on rankings.
Why Is It So Important?
There is no doubt that there is no better way to express the uniqueness and the personality of your company through real pictures. Stock pictures, although great when you need something quick, are often soulless and impersonal. It seems that stock pictures are in most cases instantly recognisable as such and with that recognition comes slight brand image damage. Overuse of stock pictures can convey apathy, lack of imagination, and the absence of creativity. Could it be that Google algorithms also share that view?

Have a look at the above two images. One was taken from an image library while the other we just took in our office with a normal camera. Yes, the second one is a bit rough, the lighting might be off and the desks not extremely tidy but it conveys real people, in a real working environment and Google has never seen that image before, so it's completely fresh and unique. Take a minute to go over your thought process as you scan both images. Imagine seeing them on an “about us” page. Which would you relate to more? Which would you believe more? Which one would convince you that you will be dealing with real people? Which would you trust more?
Hypothesis:
Considering the weight that Google places on high-quality, engaging, and fresh content, coupled with the fact that we know that Google’s image crawlers are clever enough to render/compare images, and when images are exact copies or very similar, we hypothesise that Google will give extra weight to articles that include original, yet unseen, images.
We believe that using unique images that are fresh on your site and your site only can be seen by Google (and users) as a sign of:
1. Ingenuity
2. Originality
3. Dedication
4. Motivation
5. Hard-working
6. Trustworthiness
All of which help differentiate your site from your competitors.
We, therefore, hypothesise that sites with unique images will have more weight given to them in the Google algorithms and consequently, assuming all other factors are equal, will rank higher both in image search and in web search when directly compared with structurally similar sites using widely used duplicate images.
Method:
As concluded with our other experiments, the logic behind this one proved to be much simpler than its execution.
We would invent a term which we would pre-confirm did not exist in Google’s index and therefore showed no results when searched. The term would be a word that had a meaning and could be used in a sentence on related sites. We chose the word [preotrolite].
We then defined the word as:
Preotrolite - the art/methodology of designing a well-flowing car park which takes into consideration volume, space, direction and flow.
We would create 10 sites in total. 5 containing duplicate images only while the other 5 would contain unique images only. We would then compare how the two sets of sites rank across a 3-month period.
How We Did it?
The first thing to do was purchase the domains. After ensuring all the domains consisted of fabricated words, all unknown to Google we then went ahead and used them in a zig-zag, random fashion to further blur any footprints or age-related biases. Furthermore, all domains were registered on different registrars.
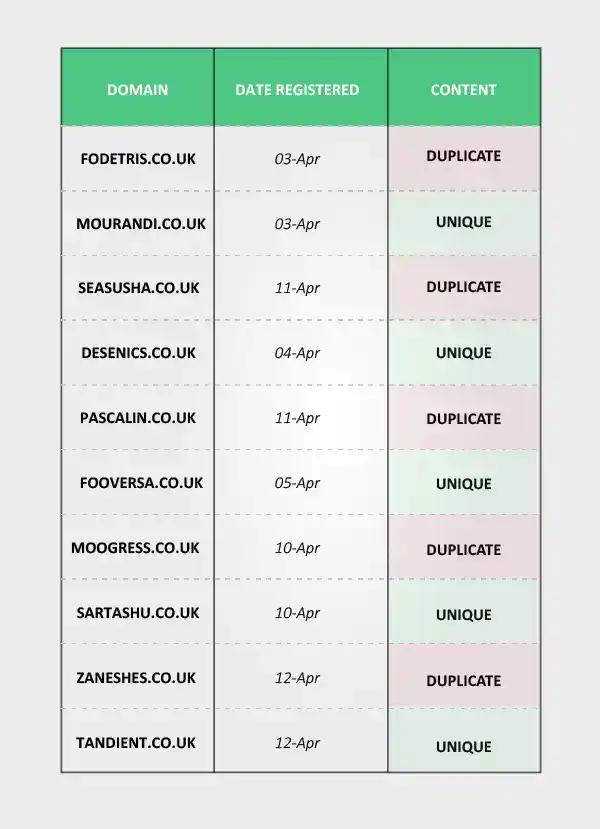
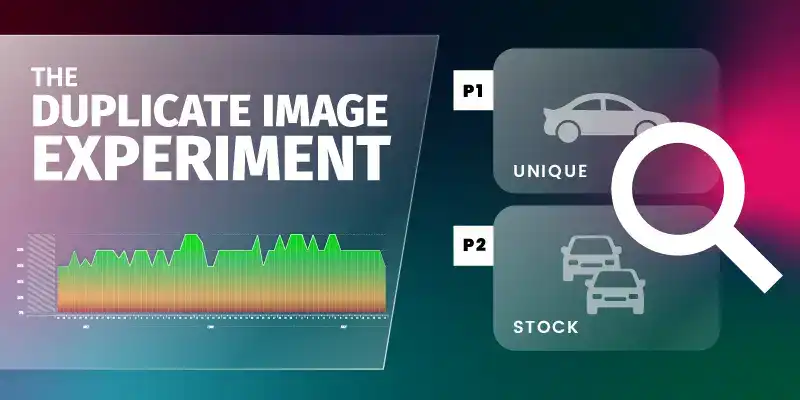
Next, we wanted to add 10 images to each site. On 5 sites, we would use duplicated images and on the other, we would use completely unique images. A total of 100 images were needed.
We painstakingly combed through hundreds of images of car parks on repositories such as Google images and other image-sharing websites. Each image was then searched through Google images to see how many results it produced. We picked out the ones that had most sites using them
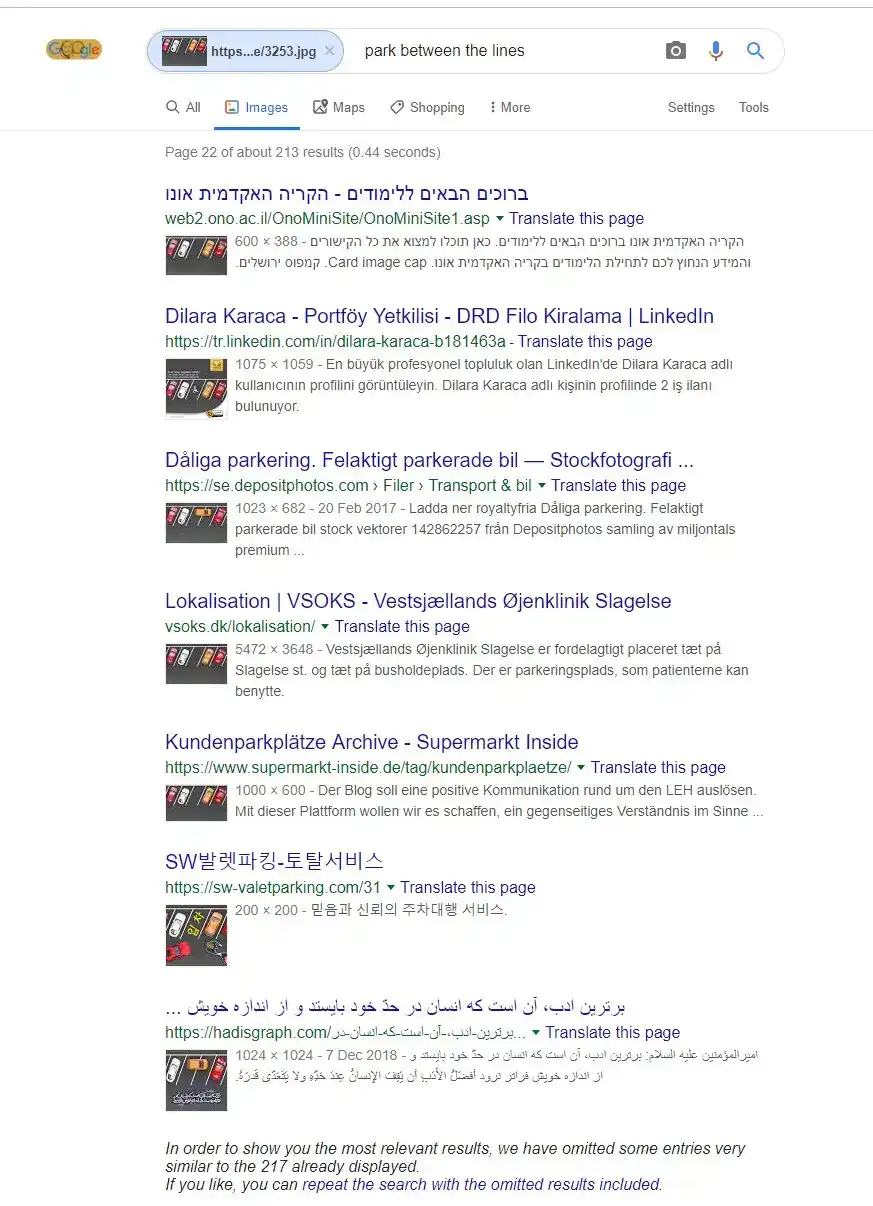
In the following example of a duplicated image used for a duplicate image site, we can see that this particular image is used in 213 other websites AND Google seems to have more results that have been omitted:
Once we had 50 duplicated images, we went out armed with a camera and took 50 more images of the surrounding car parks around our office. Here is a comparison of how Google sees our unique images once uploaded and an image search is performed:
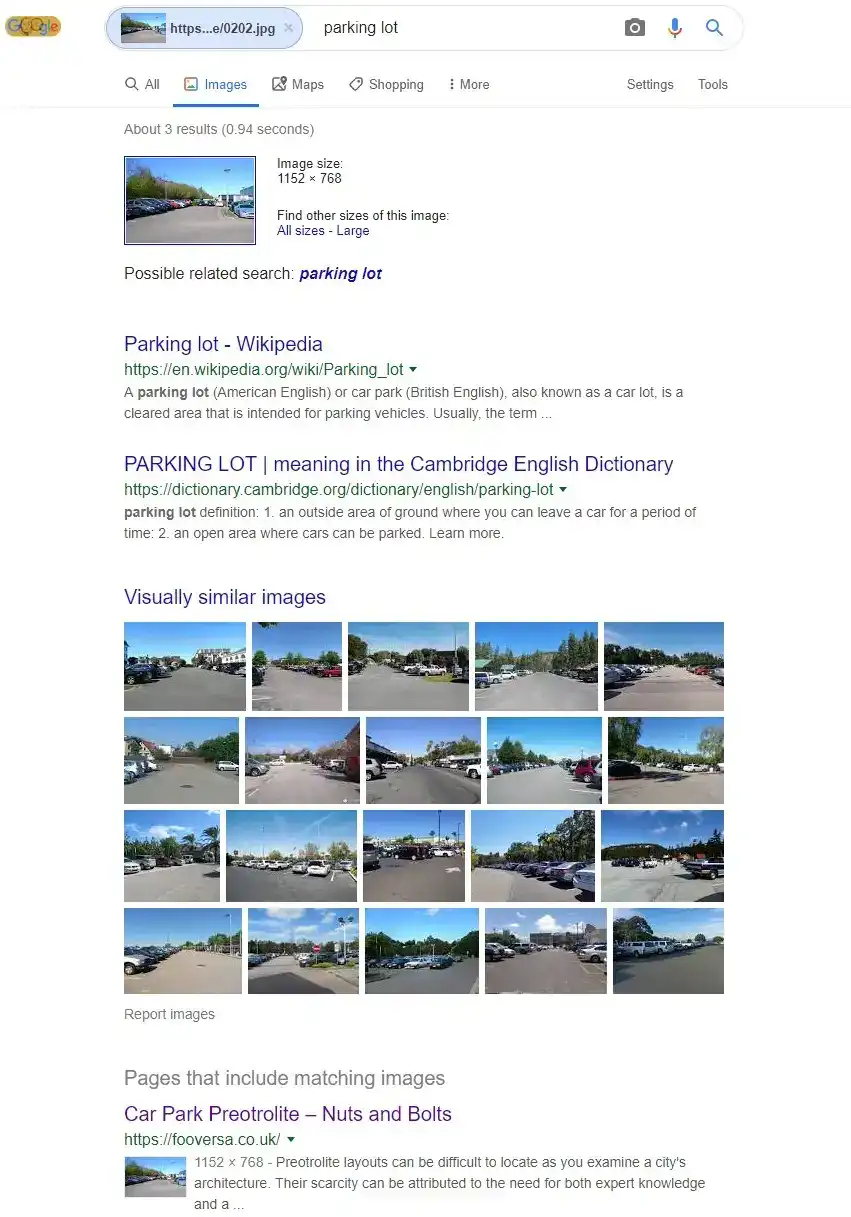
As you can see, even 3 months after the start of the experiment, the images are still seen as unique with only one result showing for the actual image towards the bottom of the page
Now we needed some minimal content on each site to encapsulate the keyword we were targeting.
It was important to ensure our keyword [preotrolite] was represented on all of the sites in a very similar fashion. We wanted them all to have the exact same occurrences of the keyword but also to include them in similar positions across the structure of the site.
This was not only a consideration for the main content of the site but also within the H1/H2 tags and title/description tags.
Here is a representation of two sites side by side (images removed for space reasons) which demonstrates the care we took to minimise any differences across the sites.

Note about Hosting:
Previous experience has shown us that when running these types of experiments, it's vital that the sites do not reside on the same host/IP address. Furthermore, as we endeavour to minimise all other external influences, we struggled with how to find 10 hosts that have similar performances so as to reduce any speed-related variables to a minimum. We, therefore, decided to use separate AWS EC2 instances located in various geographical areas and all with different IP addresses\classes. This ensured we not only maintained a similar level of performance but also that no other sites were hosted on the same server.
Precautions:
The experiment was due to run for 3 months in total. During that time, apart from myself, Oliver Sissons (Head of SEO) and Scott Bowman (Graphic Designer), no one else outside our SEO company had details of the domains or targeted keywords. This was done to ensure that no “rogue” visits to the site could influence the rankings in any way.
Brian Dean, who volunteered as an observer of the results tracked via SEMrush, was given the full information about the experiment on 19th July 2019.
We also sent emails with details of the experiment to a few data visualisation experts and other assistants.
We, therefore, consider the 17th of July to be the last day of the experiment.
Other precautions included:
- Hosts - All sites hosted on different IPs/classes on AWS/EC2
- All domains registered on different registrars
- Keyword to be tracked is unknown to google at beginning of the experiment
- All sites had Google search console accounts created on different Ip addresses and different dates and under different names.
- Domain names unknown to google at beginning of the experiment
- All text used on site is very similar in length
- All keyword mentions in similar positions across sites
- Similar but not duplicate site structure and code
- No external visitors to sites until the 17th of July, to ensure no CTR/bounce/Time on-site or other metrics can affect rankings
- Meta info stripped from all images
- All domains are new and have never been registered
- All domains have no historical links
Results:
The results are conclusive. Using unique images on your website does have a positive impact on organic web rankings as well as image rankings when compared with equivalent sites using duplicated images across the web.
The strength of this impact is difficult to gauge but the graphs below attempt to showcase the results in the best way possible.
The first graph is the hardest to explain but perfectly displays the results of the experiment in one visual. Special thanks go to Noah Iliinsky who helped with the below visual.
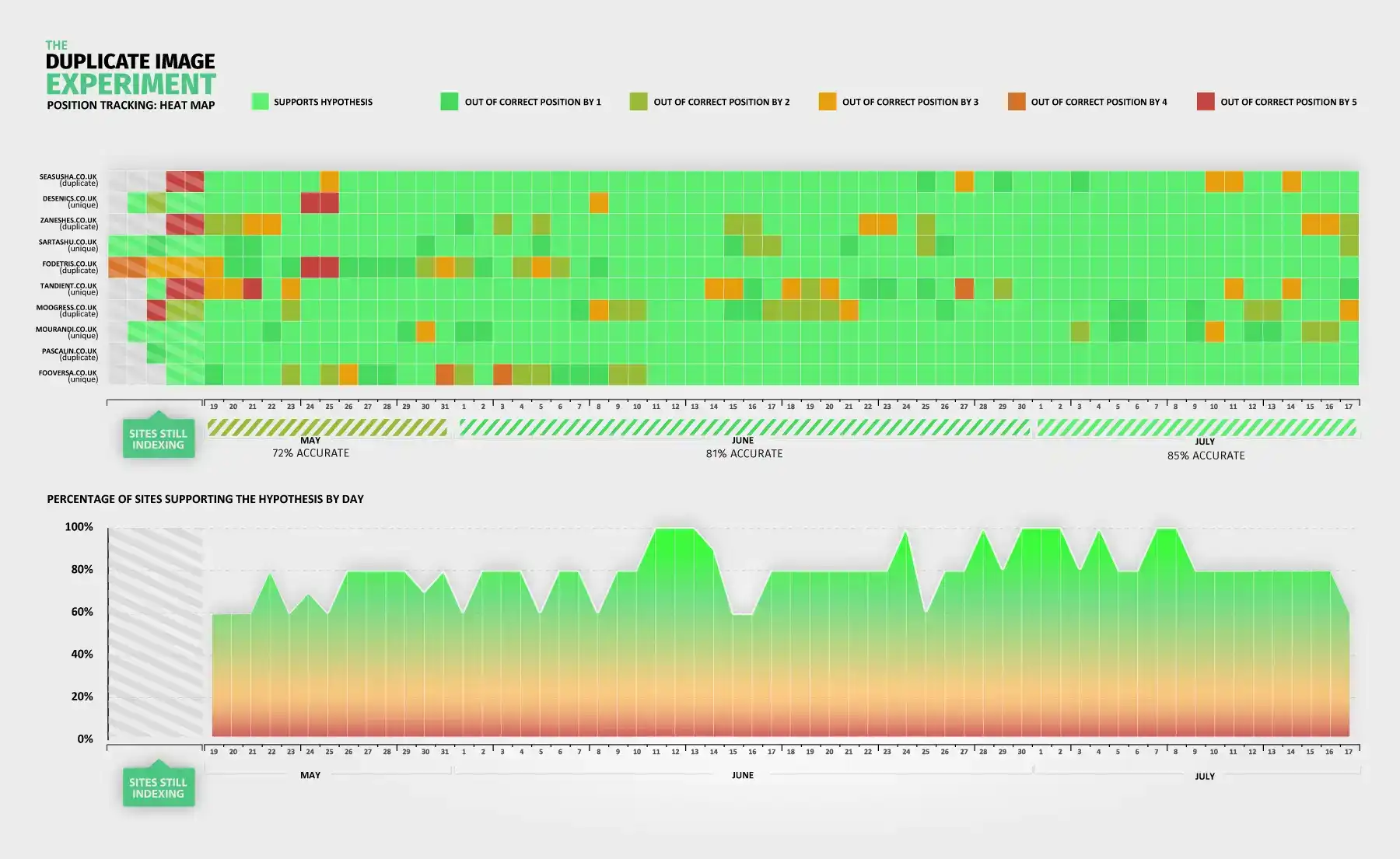
Graph reflects organic web results
Each column represents a day in the experiment. Each row represents a website. A bright green block represents the site being in the correct organic web position according to the hypothesis. i.e if a unique site is in the top 5 positions or a duplicate site is in the bottom 5 positions.
The bottom graph corresponds exactly to each day on the 1st visual and shows the results according to the hypothesis in simple % terms. 100% means all sites correspond correctly to the hypothesis and so on.
As you can see from the graph, at the beginning of the experiment, May had a score of 72% correct, June raised to 81% and July peaked at 85% correct according to the hypothesis. Surprisingly clear-cut results.
The second graph is a simple line graph directly representing the ranking of the sites on SEMrush over the 3-month period.
![]()
This graph simply splits the sites into two groups. Unique = green and Duplicate – red.
As you can see, it’s a far “busier” graph and harder to decipher but still clearly shows the dominance of the green lines towards the top 5 positions in Google.
Unlike the other visuals, the third and final visual looks at the image search results rather than the organic web results. It’s a screenshot of the results for the keyword image search [preotrolite] with green or red highlight superimposed to demonstrate if the image is a duplicate or unique image.

As can clearly be seen, unique images get a preference in Image search as well as web results.
Conclusion:
As per all our previous SEO experiments, it's important to note that in order to minimise outside variables, we had to strip everything to the bare minimum (from the on-site to the off-site, for example, no links were pointing at the sites hosting the images given how much impact links could have on where they ranked, as any digital PR agency would tell you). This means that although this experiment shows a clear advantage for sites with unique images, it does not convey in any way the strength this advantage has in comparison with other signals. The use of stock images is something that is widely accepted across the web and although an advantage for unique images can logically be explained, there is still doubt on the real-life impact this may have on a case-by-case basis.
Would we encourage you to go out and take some pictures yourself for your blog or small ecommerce site? Well, the answer to that is “it depends”. If you can do so cheaply while maintaining quality and actually offer something new to your visitors, then definitely YES. If, however, you have thousands of products and would need to invest vast amounts of money into equipment and know-how, then the answer is far less conclusive and would be best made after some individual testing in your own environment.
Thanks:
Special thanks go to Brian Dean from backlinko.com for acting as an observer of results and SEMrush ranking data.
Page Updated - What Has Changed?
In the interest of pursuing perfection, we have updated some aspects of this blog post to correct grammatical errors and to include updated links.