

POST
AI vs Humans - The SEO Content Experiment
ChatGPT, the chatbot created by OpenAI following over a decade of research and technological advancements in the fields of machine learning and artificial intelligence, launched on the 30th of November 2022 and took the world by storm.
It hasn’t taken long for SEOs to begin thinking of ways to integrate powerful new AI technology into their on-site and off-site campaigns. In fact, according to recent content marketing statistics and AI in marketing statistics, 72% of marketers have already started incorporating generative AI tools into their content creation processes.
With so many SEO companies rushing to use AI in their on-site content campaigns, and without any robust testing on how it performs relative to alternative approaches and strategies, it is no surprise that we have seen countless case studies proclaiming both the positive and negative SEO impact that AI generated content has had:
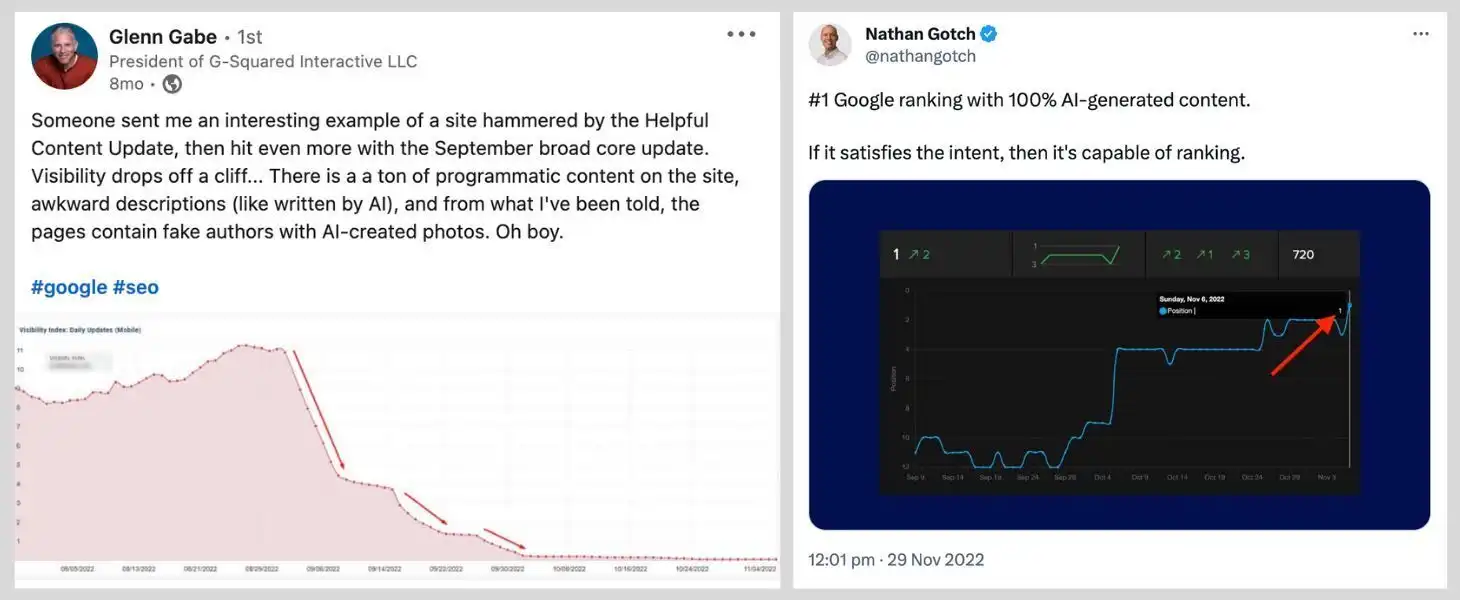
Shown above is a case study by Glenn Gabe highlighting the negative impact of AI content and one by Nathan Gotch highlighting the positive impact.
SEO is nuanced, and how you use AI will ultimately be the deciding factor on if it will help or hurt your SEO efforts. However, the question remained, would Google rank AI generated content any better or worse than content created by a human?
The expert GEO agency team at Reboot have spent the last 3 months setting up and running a controlled SEO experiment to test whether, with all else being equal on-site and off-site, there are any differences in rankings between the two types of content. Learn how insights from this experiment align with the principles outlined in the Geo Playbook.
Below we will look at our hypothesis, the methodology used to run this experiment, and the results.
Hypothesis
Our hypothesis was that, in a controlled environment with no outside factors influencing the perceived quality of a given website, AI and human content would perform equally.
It wasn’t obvious that Google would even be able to identify if a new piece of content was generated by AI or written by a human. Also, since using AI to generate content in and of itself is not against Google’s guidelines, it also wasn’t clear that the use of AI to generate content would impact rankings in any way.
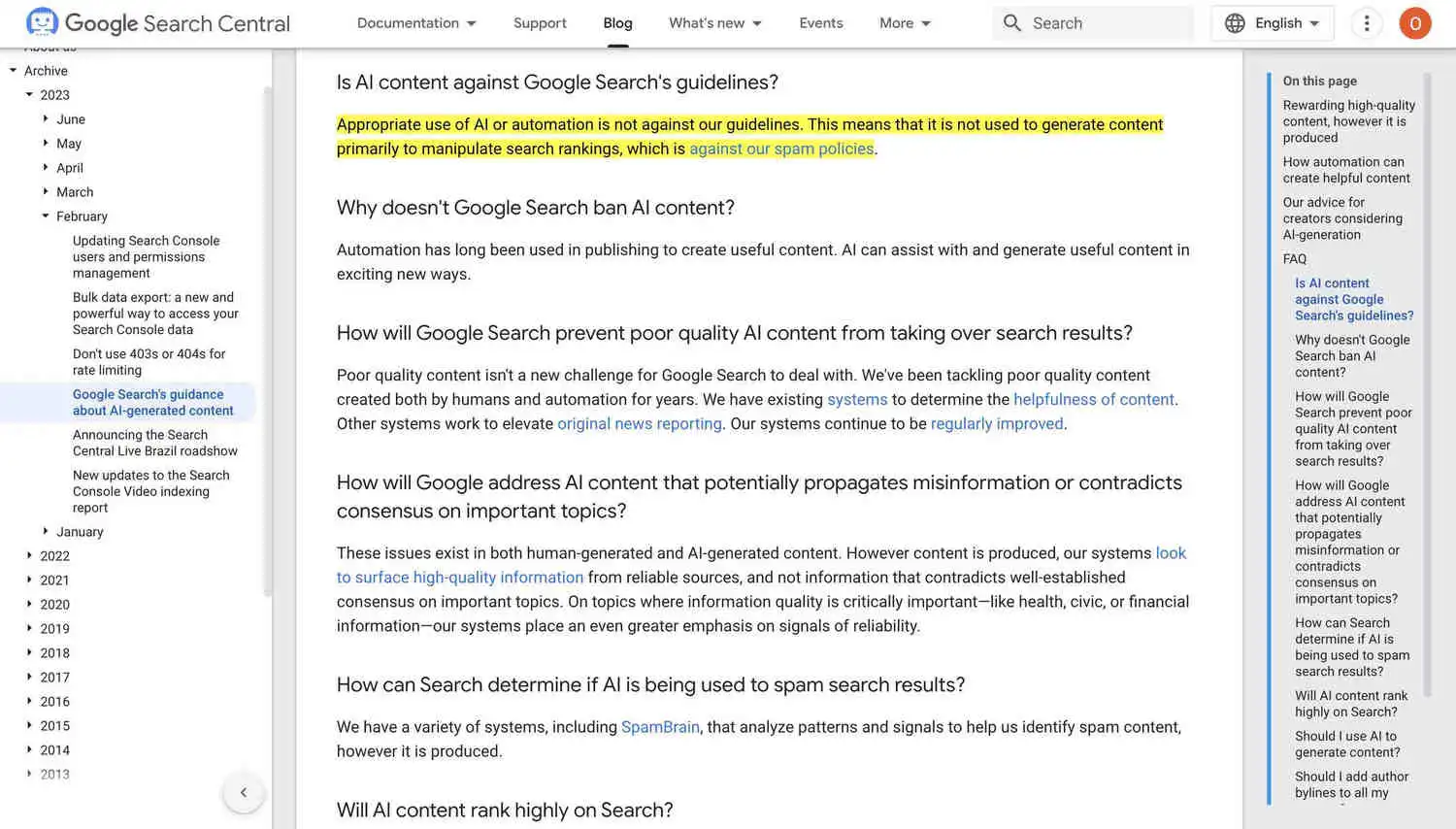
Google documentation which confirms that use of AI and automation alone is not against their guidelines.
From our hypothesis we knew that the objective of the experiment would be to isolate the use of AI generated content as the independent variable.
By successfully isolating the use of AI content as the independent variable, we could find out what impact (if any) this had on the rankings of the test domains.
Methodology
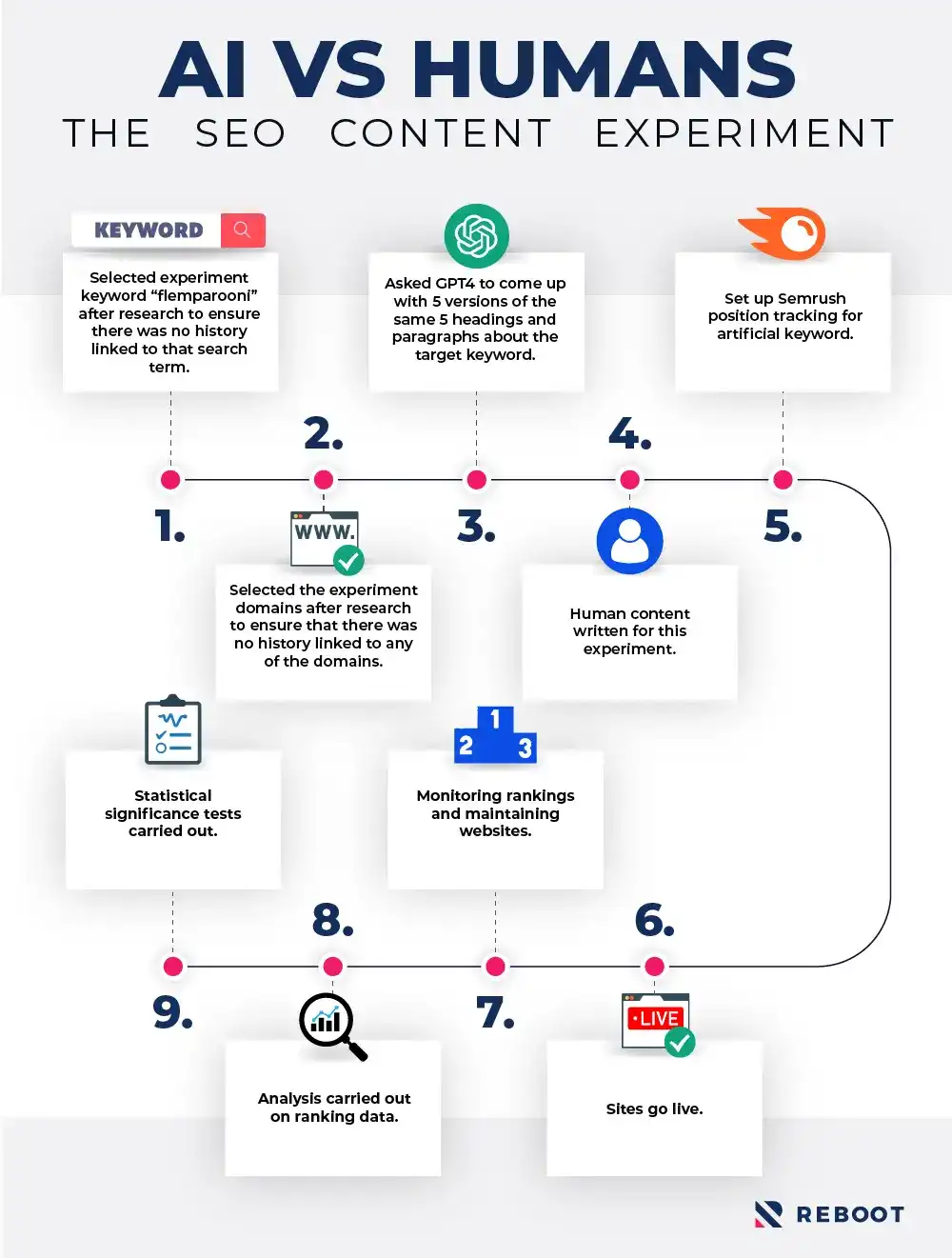
As with all of our SEO experiments, the first step in testing our hypothesis was planning a comprehensive methodology which would effectively isolate other ranking factors whilst allowing us to test our independent variable properly.
Below we have gone into detail on exactly what our methodology looked like and all of the things that we had to consider when carrying out the experiment.
Selecting the Test Keyword
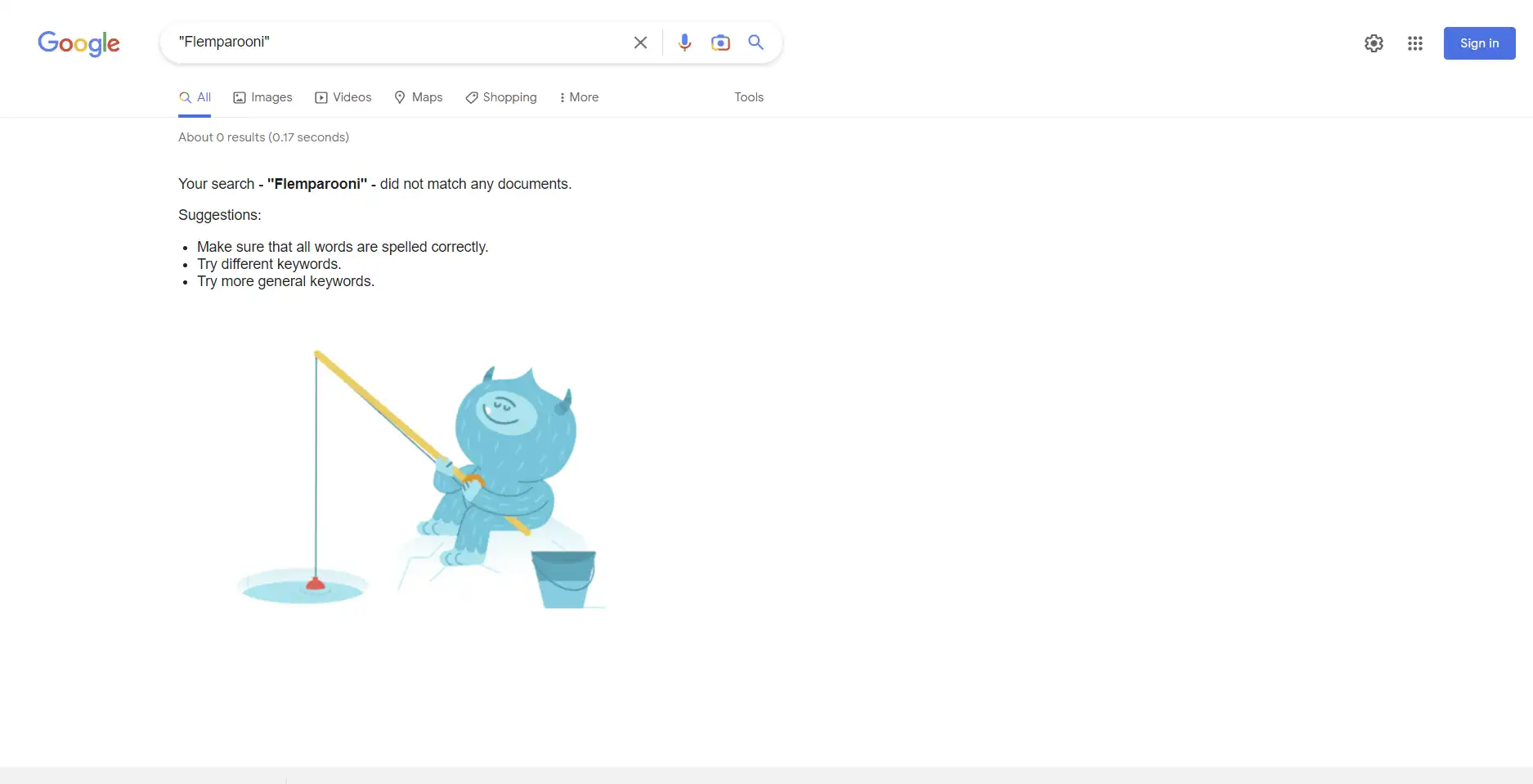
A Google search of our test keyword before the experiment began returned no results.
We knew that targeting a real topic and keyword in this experiment would risk introducing outside ranking factors which we can not control.
For example, Google’s algorithms might take into account a multitude of factors like content factualness relative to other published content about the topic, and/or the writing styles of other trusted websites discussing the topic, in determining where to rank our experiment websites.
For this reason, we decided that using an artificial keyword would be the best approach.
Artificial keywords are search terms that we can confirm are unknown to Google before our experiment. When searched, they return no content in Google’s index prior to our test websites being published.
Fortunately, ChatGPT itself came in handy when coming up with our artificial keyword for this experiment.
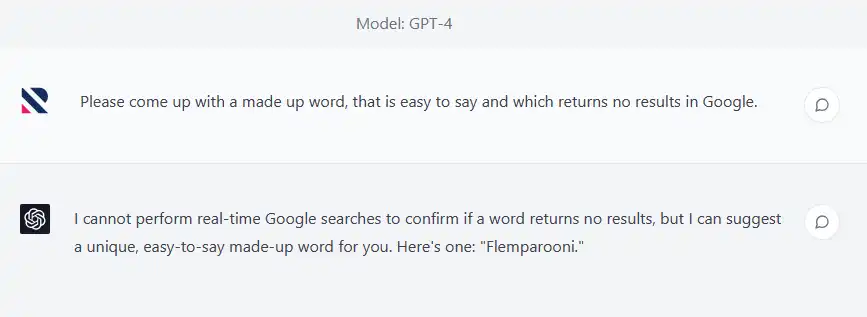
We used ChatGPT to come up with our test keyword.
We used ChatGPT to come up with a made up keyword, “flemparooni”, which we then researched to ensure that it fit our experiment criteria (that is was not known to Google before the start of our test).
Selecting the Test Domains
Next, we needed to come up with domain names for our test websites which fit our criteria to remove the risk of domain-level ranking factors impacting the experiment results.
We used ChatGPT again to come up with a seed list of domain names that used made up words.
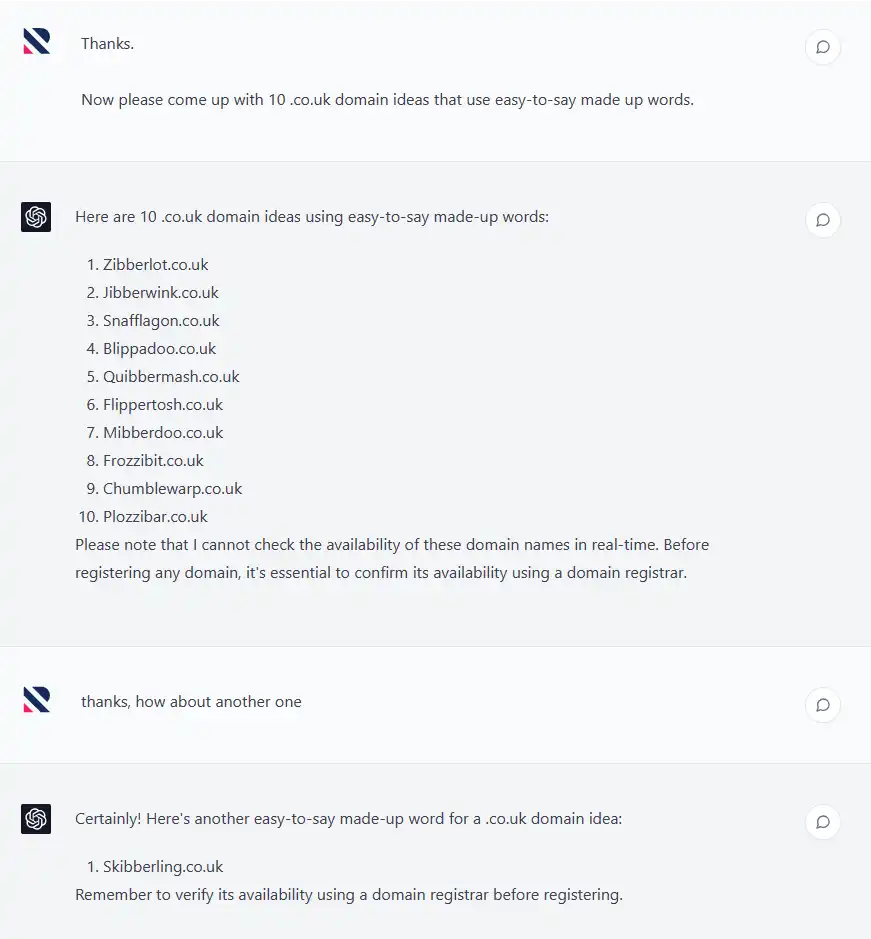
We used ChatGPT to come up with a seed list of experiment domains.
We excluded one as it returned some broad search results when we looked for it in Google’s index, and you can see in the screenshot above that we requested ChatGPT give us another domain name idea as a result.
With our seed list to hand, we then researched each domain name to confirm that the domains we selected did not have any historic ranking signals associated with them.
We used Archive.org to check that no website had been published on each domain previously:
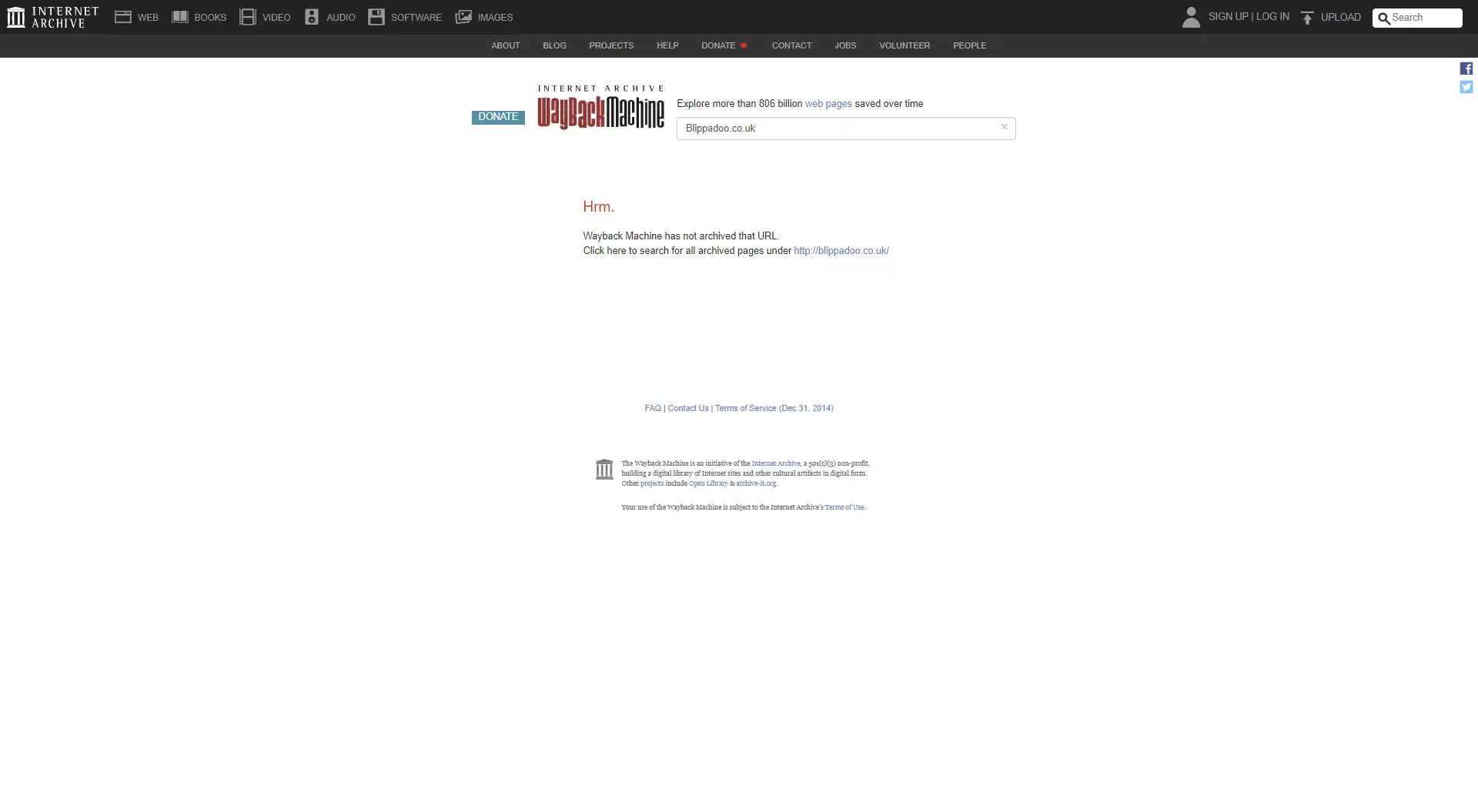
We used Archive.org to confirm that our experiment domains had no known history associated with them.
We also used third-party SEO tools like ahrefs, Majestic SEO, and Semrush to confirm that none of the domains had any external backlinks pointing to them or historic rankings in the Google Search Results:
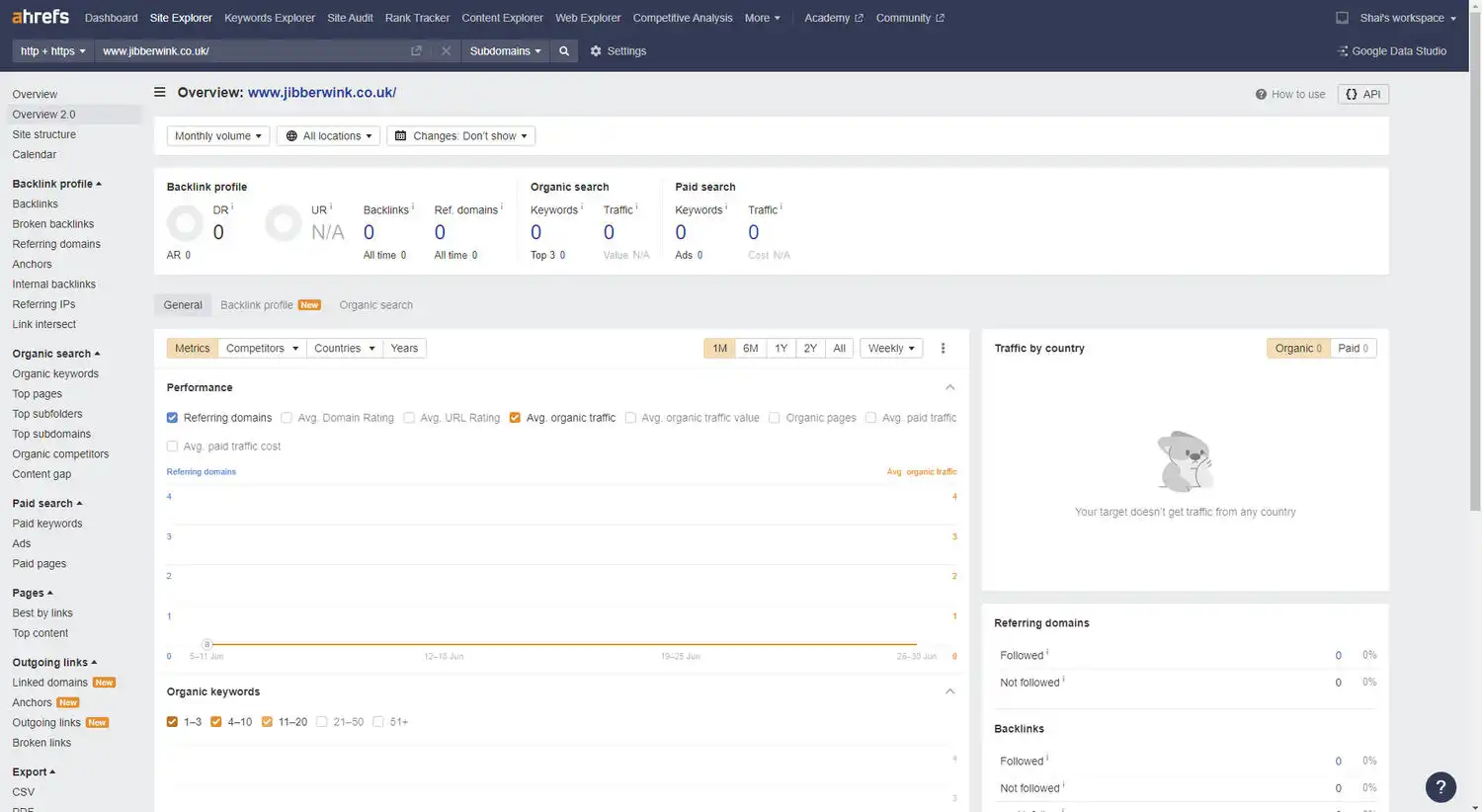
We used ahrefs, Majestic, and Semrush to confirm that none of our experiment domains had any external backlinks pointing to them.
Analysis throughout the experiment confirmed that none of the test websites picked up any external links.
Finally, we searched Google’s index to check that no other results were returned which would suggest that, at some point previously, the domains were known to the search engine:
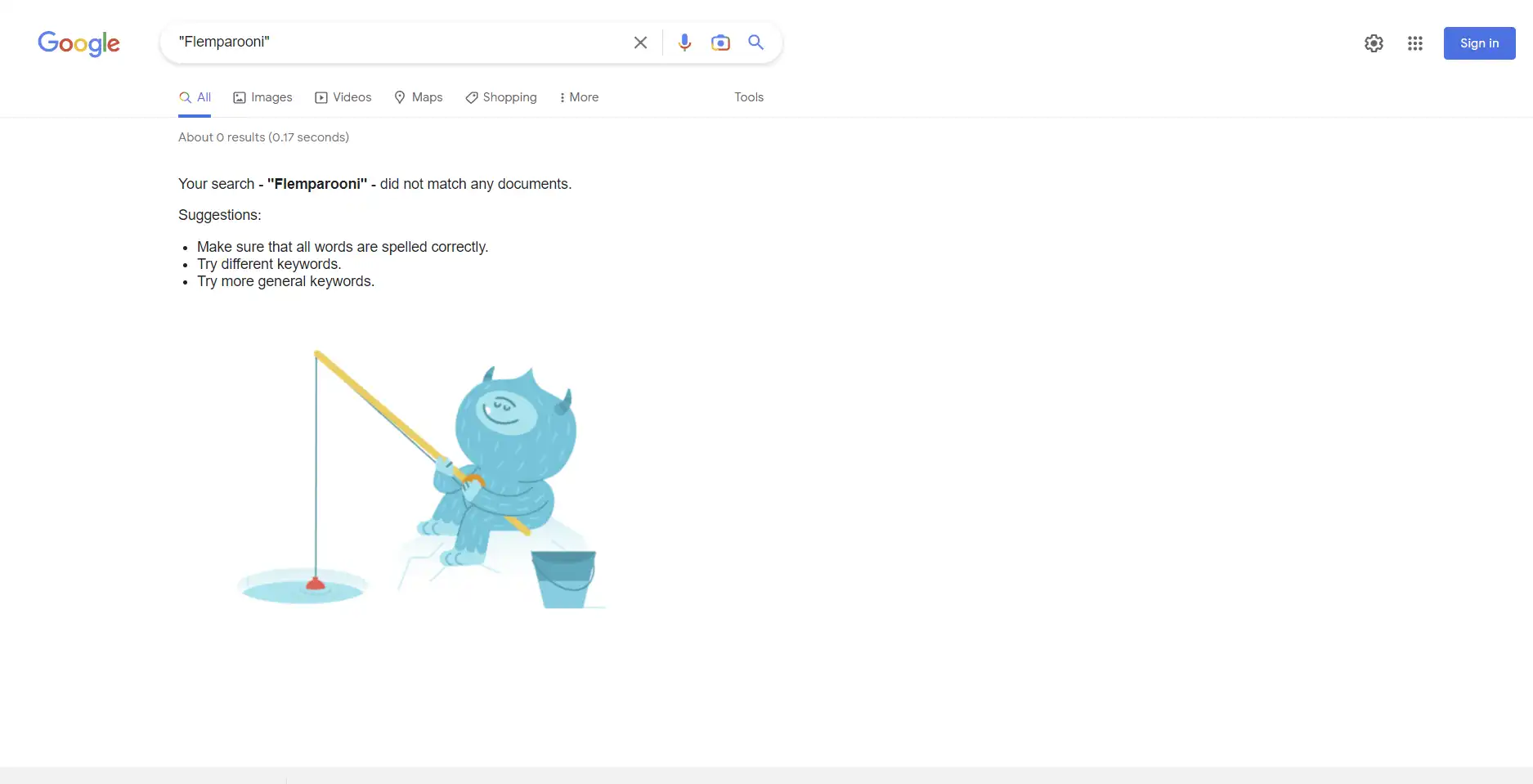
A Google search showing no results for a search of one of our experiment domains.
All of these checks enabled us to proceed with the experiment knowing that no external and/or historic ranking signals would influence our test results and sway the rankings of the experiment domains.
Our Final Test Domains:
- Zibberlot.co.uk (AI)
- Jibberwink.co.uk (AI)
- Snafflagon.co.uk (AI)
- Blippadoo.co.uk (AI)
- Quibbermash.co.uk (AI)
- Mibberdoo.co.uk (Human)
- Frozzibit.co.uk (Human)
- Chumblewarp.co.uk (Human)
- Plozzibar.co.uk (Human)
- Skibberling.co.uk (Human)
We decided to run our experiment with 10 test domains, 5 which would contain AI content and 5 which would use human content.
Creating the Test Content

We ensured that the AI generated content and the human written content was equally optimised for the test keyword.
With our artificial keyword and test domains selected, the next step was to create the AI and human content which would be published on each domain.
We had to follow strict guidelines when creating both the AI and the human content to ensure that there were no differences in the optimisation of the websites which would result in them ranking differently due to changes unrelated to the way in which the content was generated.
Content Creation Guidelines
Below we have listed some of the guidelines that we used to ensure that all of the test content was equally optimised for the target keyword:
- All of the content must contain the same number of mentions of the target keyword.
- The keyword mentions must occur in the same place in each piece of content.
- The underlying meaning of the content must be the same across each website (e.g. one piece could not express positive sentiment where another expresses a negative sentiment).
- Each website must contain content of roughly the same length.
- Each website should contain the target keyword in prominent positions to make it optimised for the search term, without violating the second point.
- No internal or external links should be included in any of the content.
- None of the test domains should contain any additional content, pages, or authority/trust signals (e.g. no NAP).
We created the AI generated content in the SEO team while working closely with our content marketing team to create the human content. Each piece of content was reviewed against the guidelines listed above to confirm that they were equal in regards to their keyword optimisation.
Generating the AI Content
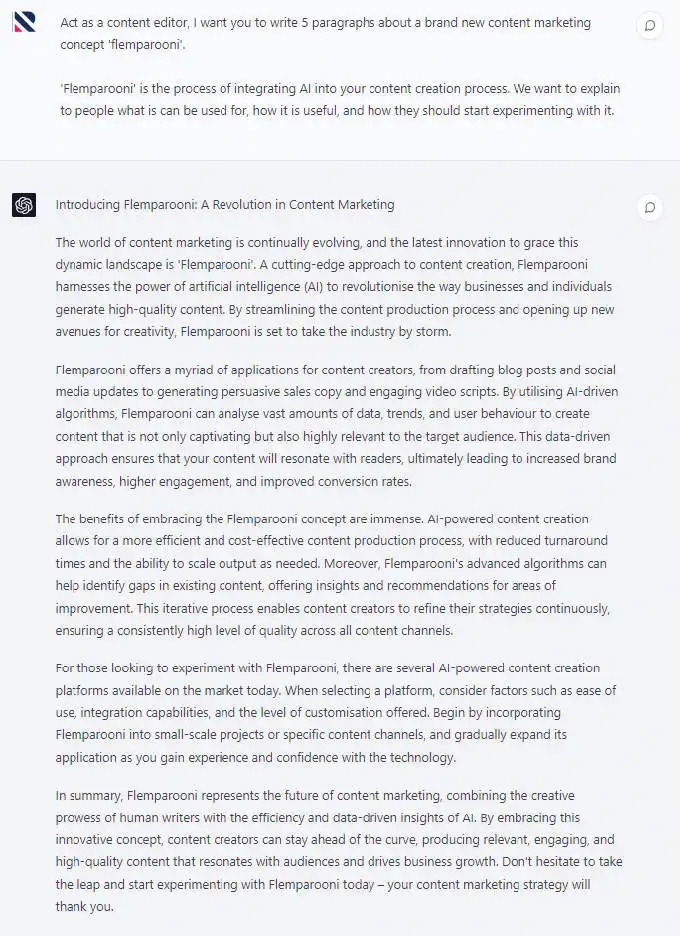
We used ChatGPT, model GPT-4, to create the AI generated content.
First we crafted a prompt which we could then input into ChatGPT to generate the AI content used in this experiment.
As expected, ChatGPT had no problem spitting out 5 variations of our desired content, and delivered on what we had requested with remarkable consistency.
The similarity between the AI generated content meant that it remained well within our content creation guidelines.
Writing the Human Content
We provided guidelines to our content writers to ensure that the content they created was just as optimised for the test keyword as the AI generated content was.
Our content marketing team has helped us deliver multiple SEO experiments over the years, so they were well versed in how to write content suitable for these kinds of experiments.
We provided a brief for the content creation which ensured that the created content would be just as optimised as the AI generated text, but the human content writers did not see the AI generated text prior to writing their content.
The team set about writing the 4 additional variations that we required for our test sites and, within a day of it being requested, we had all of the test content that we would need for this experiment.
Comparing the AI & Human Content
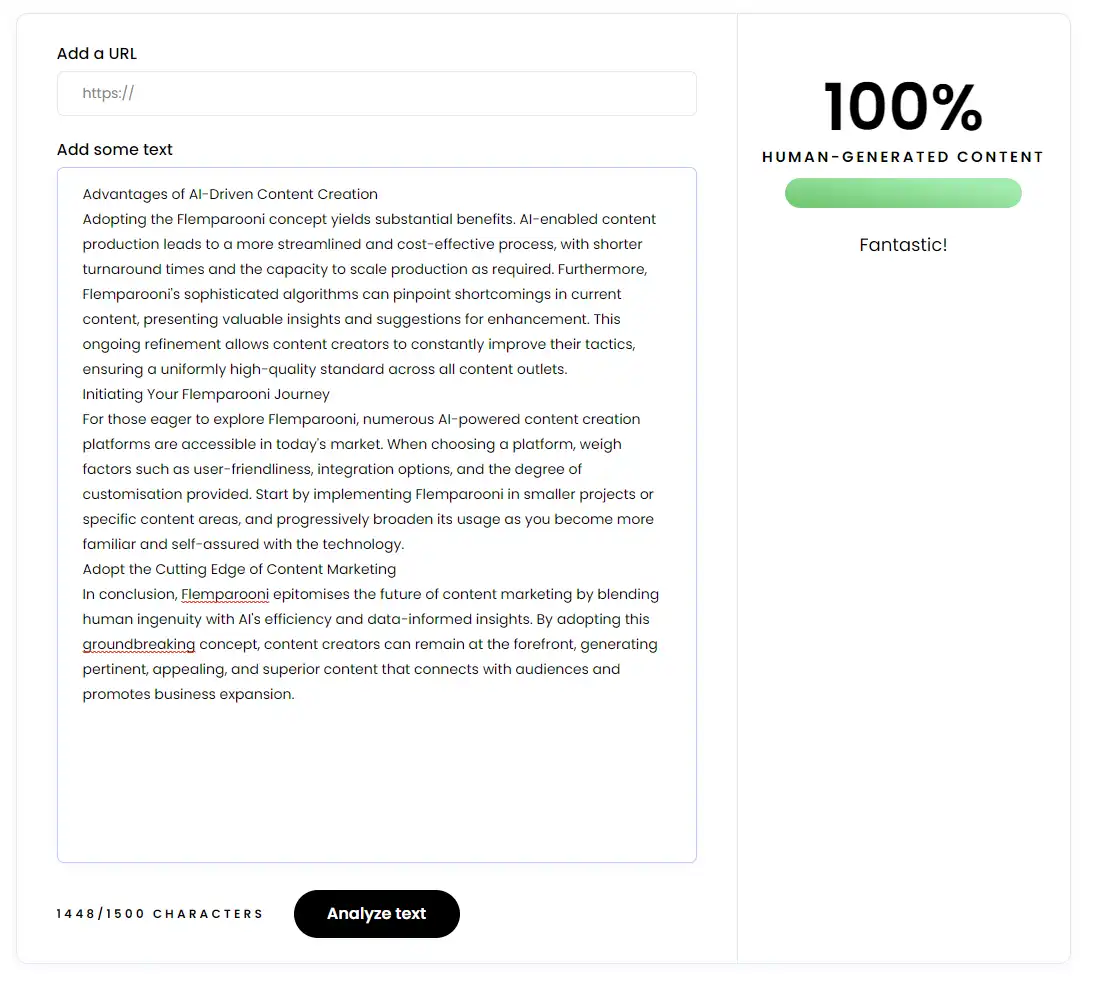
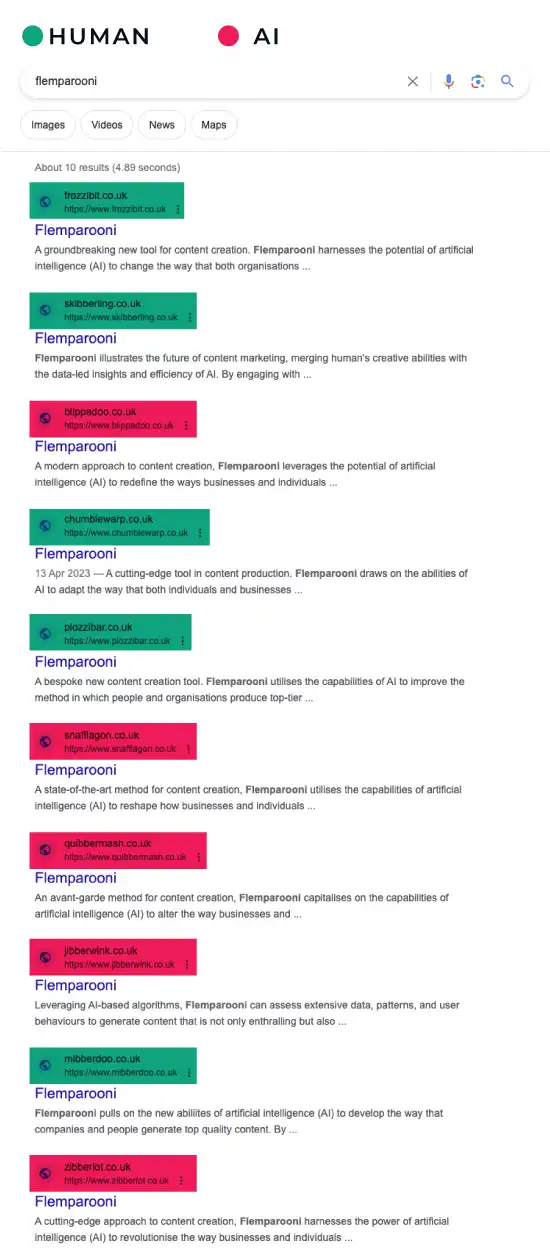
We used AI content detection tools to see if the tools available at the time could identify our AI generated content (they could not).
Even though we wouldn’t really know if Google could tell the difference between our AI test sites and the human written ones until after they were indexed and ranking, we were still interested to find out how good the third-party AI content detection tools available were at detecting it.
We ran all of the AI generated and human content through multiple online AI content detection tools and, at the time, none of them correctly identified any of our AI content.
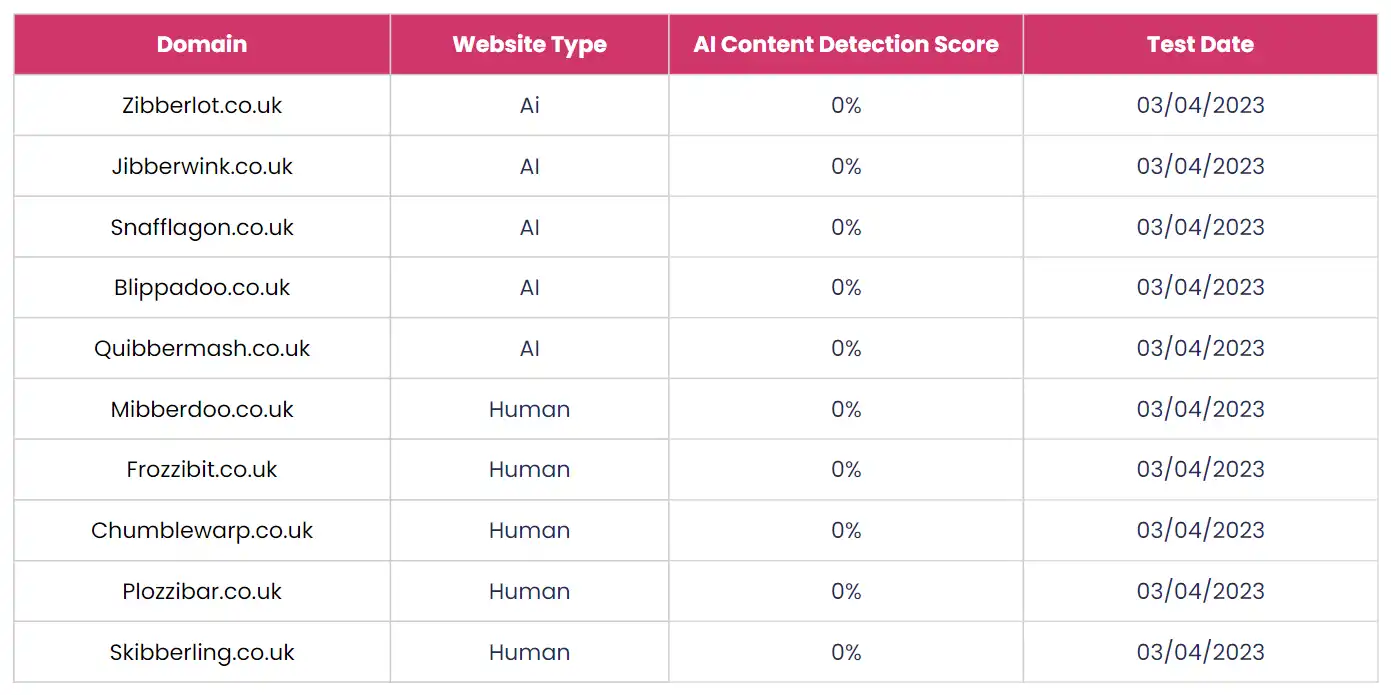
The GPT4 model had not long come out and we suspected that the content detection tools had not yet caught up with the latest model.
Interestingly, when we went back and retested all of the websites while writing up this experiment, the tools did pick up the AI content much more consistently.
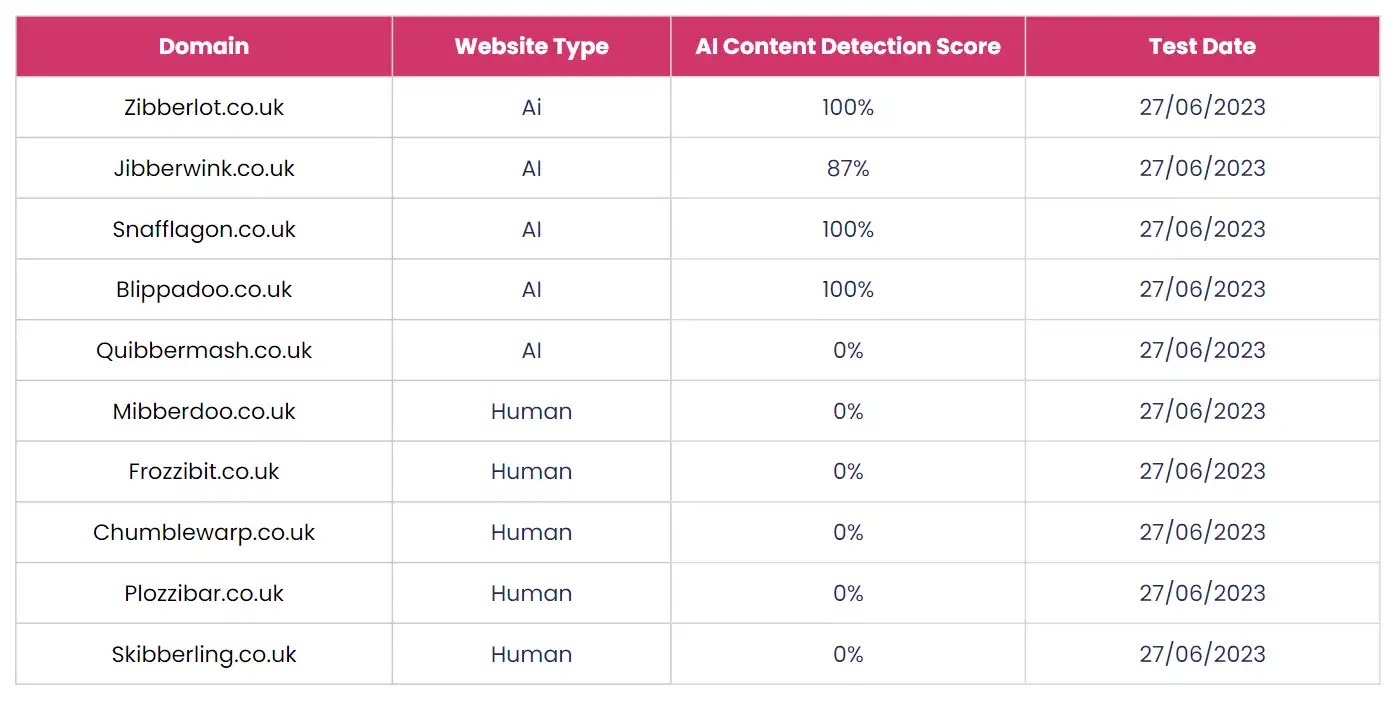
In our tests post-experiment, the Crossplag AI Content Detector tool only failed to detect one of the AI content websites. It also correctly identified all of the human written ones (as had been the case at the start of the experiment).
It would appear that the third-party AI content detection tools are getting much better at identifying content that has been generated by the more advanced large language models.
Given the rapid pace of improvement of this technology, it is great to see the detection tools also making such strong progress within a relatively short amount of time (3 months).
Publishing the Test Websites

With our content ready, the next step was to publish the test websites.
Taking learnings from our previous experiments, we ensured that each of the websites was published in a way that did not introduce any direct or indirect ranking signals which would make our data less reliable and accurate.
We used a simple and similar HTML template for each website which looked nearly identical, with only small styling changes (e.g. a different font and background). The templates used unique CSS class and ID names also so that they were not completely identical/exact duplicates.
Each domain was hosted on AWS with only a different C class IP, to keep speed and performance scores equal across the websites.
We used StatusCake to ensure that the speed, performance and uptime of the test websites remained equal.
We used StatusCake to run hourly speed and uptime tests throughout the experiment to ensure that speed and performance scores remained equal across all of the domains throughout the course of the experiment.
Minimising Outside Ranking Factors
Below we have summarised the ways in which we minimised the risk of outside direct and indirect ranking factors influencing our test results:
- Fresh domain names with no external backlinks pointing to them.
- Domain names had never before been indexed/known to Google.
- Domain names had never had websites hosted on them.
- The use of a new artificial keyword to minimise any E-E-A-T related factors.
- Equally optimised content across each website.
- Near identical HTML and CSS to keep speed and performance consistent across the test websites.
- Launching of the test websites on the same day/within the same hour to stop any age related factors influencing the results.
- Hourly speed and uptime checks to ensure speed/performance was equal.
- Same hosting setup for each website (all hosted on the same AWS instance and using Cloudflare).
- No searches of the keyword throughout the entire test period (we used external tools for rank tracking).
- No one outside of our SEO company knew of or visited the test domains throughout the experiment.
The ability to minimise any influence of ranking factors outside of our independent variable in this way is what makes these controlled experiments so tricky to run, but also is what makes their findings as accurate as possible.
Rank Tracking & Reporting
![]()
We used Semrush to track the rankings of our test websites.
To avoid introducing any potential influence from engagement signals with the SERP for our artificial keyword, we made sure that no one searched the test keyword throughout the course of the experiment.
We used Semrush to track the rankings of our test sites, and referred to this data when analysing the results.
All of the test websites were tracked within one Semrush position tracking campaign, ensuring that the rankings were updated at the same time and that no localisation and/or personalisation factors would influence the data.
Rank tracking was run once per day for the duration of the experiment.
Results
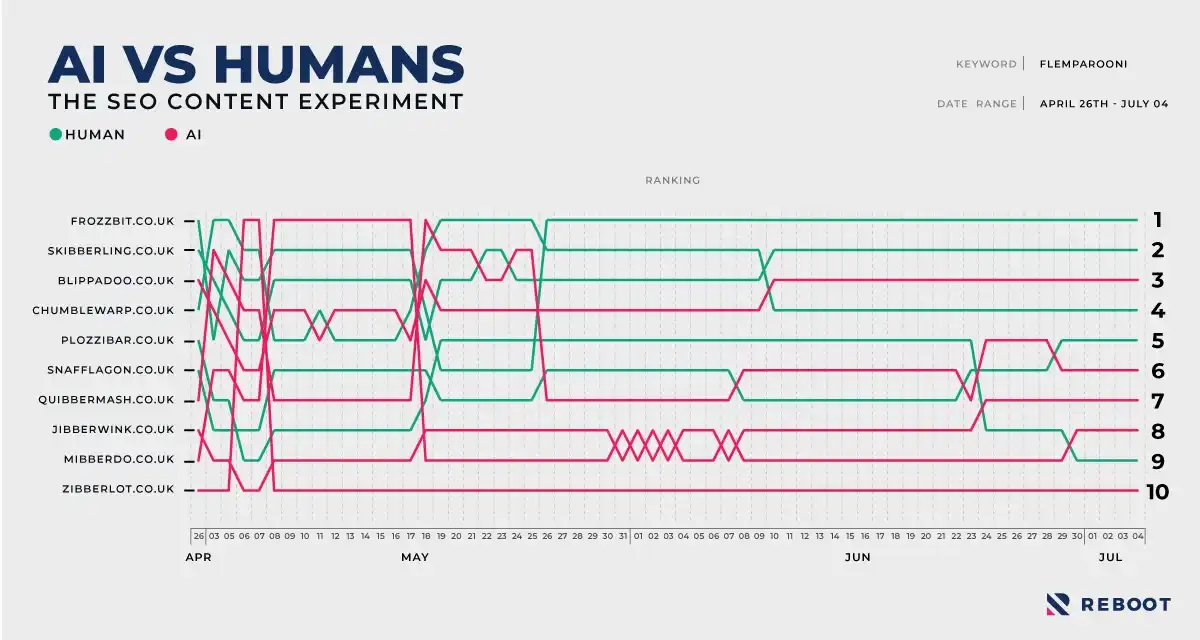
We also put together an interactive version of the rank tracking graph.
The rank tracking data shows clearly that the human written content ranked better than the AI generated content.
If we look at the data from when all of the test websites ranked for the target keyword onwards, the AI generated domains had an average ranking of 6.6 whereas the human written domains had an average ranking of 4.4.
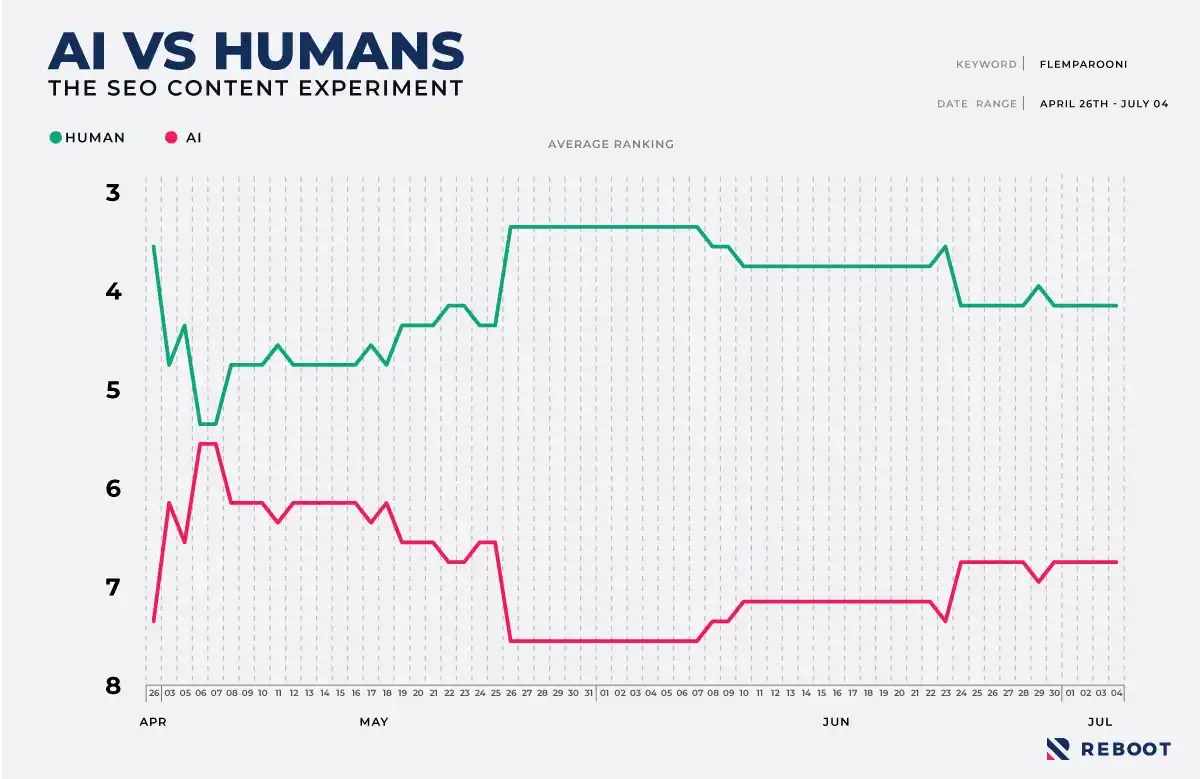
While it was very interesting to see the human written content domains outranking the AI generated content domains, next we needed to work out if the results were statistically significant.
Statistical Significance
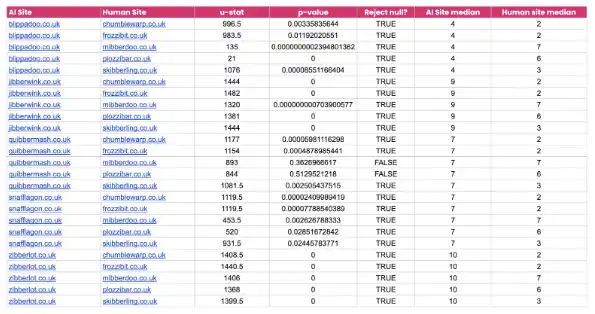
We asked our data team to review the results and check if they were statistically significant. They decided to run a Mann Whitney U test which would indicate whether one kind of website (the human content domains) tended to produce better rankings that the other kind of website (the AI generated content domains).
Below is what our Data Analyst Jake Teague had to say:
The Mann Whitney U test indicates whether one population tends to produce higher values than the other population.
"The null hypothesis for this test is that, by randomly selecting values from two populations (in this case SERP links for AI or Human sites), that the probability of X being higher than Y is the same probability of Y being higher than X. In short, it is essentially a test of median’s within each population, to measure if they are the same or if they are different. In this case, a population is the ranking of that website over time, where a lower value means a higher ranking.
A Mann Whitney U test returns a U-statistics, which is an indication of just how different the medium of the two populations are from one another. A larger U stat indicates the AI site ranks lower than the human site, whereas a smaller U stat (closer to 0) indicates that the AI site has a higher overall ranking than the human one.
For 5 AI and 5 Human websites, each pair of AI/Human websites were tested, for a total of 25 tests. The values of each population were measured from the point at which ranks were generated (so values of 0 were excluded).
Over all of the tests carried out, 92% of the time we rejected the null hypothesis. Essentially meaning that there was a statistically significant difference between the medians of the ranks for the AI and Human websites.
Further investigation of the results shows that, of the 25 pairs, 1 AI website (Blippadoo.co.uk) outperformed 2 Human websites. Also, for 2 other tests we failed to reject the null hypothesis which implies that the median’s of the populations of the AI and Human websites were the same/similar. However, for the remaining 21 tests the Human websites outperformed the AI ones. This showed that a smaller median (and therefore a higher ranking) led to a larger U-stat across the board.”.
Discussion
The experiment clearly showed that the AI generated content ranked less strongly (on average) that the human generated content.
We look forward to hearing from the SEO community their thoughts and opinions on how Google may have been able to identify the AI generated content and factor that into their rankings.
We know that the large language models that we have been discussing involve (but are not necessarily limited to) next word prediction, which suggests that an algorithm could determine mathematically what text was generated in this way vs content that was not.
Implications
Of all our SEO experiments, this one has perhaps the biggest implications in the short-term for website owners, content writers, and SEO agencies.
On the one hand, the data does suggest that content creators needn’t worry that AI generated spam will be outranking them at scale anytime soon. On the other hand though this powerful new technology will inevitably bring change to the search results and the day-to-day work carried out by SEO professionals.
Already we see search engines like Bing and Google building generative AI into their search results, and it might not be long before those who drive all of their organic traffic by publishing generic informational articles find themselves competing with the search engines themselves.
Limitations
It is important to discuss the limitations of any study, and we wanted to take this opportunity to discuss some of the limitations that we observed whilst carrying out the experiment. Below we have commented on some of the limitations we identified when writing up our methodology and findings.
Artificial Keywords
The first thing to note is that we used an artificial keyword for the study, which some may see as a limitation.
Artificial keywords allow us to remove the impact from ranking factors outside of our independent variable, and they are one of the few ways to attribute any SEO causation effect to an independent variable.
However, naturally using an artificial keyword introduces the argument that there will be other factors at play when it comes to ranking real websites in an actual search engine results page. We should keep in mind that this is exactly the purpose of these experiments, to remove any outside ranking influences from the equation and to narrow our focus and identify if our independent variable has any strong impact on the rankings of the experiment domains.
Inevitably we should keep all of the above in mind when tying the experiment results back to the real world search performance of actual websites.
It is possible that some AI content domains will rank well as a result of other on-site and off-site factors, or the way in which AI is used, but none-the-less with all else being equal the data did show that human written content tended to perform better than the AI generated content (for now).
Sample Size
Another limitation is the sample size used for this study.
Running such controlled experiments is already very time, energy and resource intensive, and working with a larger sample of test websites inevitably requires significantly more time and money to be spent over an extended period of time.
Given the strict environment setup of this experiment though, we are confident that some key insights can be taken away from our small sample of test domains.
Changes in AI
Even in the time that we have been running this experiment there have been significant advancements in the field of AI.
Google has been ever more vocal about their own ambitions to use AI generated content in the search results, and new models are constantly being released by private companies and as open source.
We can see this in how the AI content detection tools have improved over the course of the experiment, now able to detect GPT-4 generated content much more reliably than they were able to when we first started the test.
It is possible that, for a time, Google will be essentially playing a game of cat and mouse to detect and manage the flood of AI generated content that is likely to be published online in the coming years. Although we also should acknowledge that Google has long been a leader in the field, and there is a good chance that they are already far ahead of what others are creating in the space.
Content Editing
This experiment also did not look at how human editing and refining of AI generated content could impact rankings, and work is actively being done already to train models to write in the same tone of voice, format and style as the business training it, which is also likely to influence how unique the generated content is.
It is possible, or even likely, that having a skilled content writer edit and personalise content generated by AI will yield better long-term results and, for now, make the AI content more aligned with your preferred brand tone of voice and style.
Thanks
We wanted to give an especially big thank you to Cyrus Shepard of Zyppy SEO who agreed to observe the experiment (and some of our previous ones).
We shared the raw data and experiment log with Cyrus who was kind enough to offer his time and thoughts on the test and the findings.
These experiments would also not be possible without the help of our content marketing, data, graphics, web development teams, and of course our managing directors Naomi and Shai Aharony who allow us to go to such great lengths in testing widely held SEO theories, myths, and misconceptions.
Closing Thoughts
The rapid advancement of AI seen in recent months has generated a lot of debate, discussion, and even anxiety throughout the agency landscape.
Sadly, it isn’t uncommon to read about the winding down of once great and large content teams as businesses look to save money by outsourcing their content creation to AI tools.
One of the key takeaways from this experiment is that content written by skilled human writers, dedicated to creating content that resonates and connects with their target audience, is still in high demand (by readers, and by search engines).
We would like to conclude by adding that we have absolutely no plans to follow the herd and will continue to ensure that our content is not only the best, but also human.
References, Sources & Tools Used
- https://originality.ai/
- https://writer.com/ai-content-detector/
- https://copyleaks.com/ai-content-detector
- https://crossplag.com/ai-content-detector/
- https://contentdetector.ai/
- https://www.zerogpt.com/
- https://openai.com/
- https://www.semrush.com/
- https://ahrefs.com/
- https://archive.org/
- https://majestic.com/
- https://www.google.co.uk/
- https://www.statuscake.com/