

POST
404 Vs 410 - The Technical SEO Experiment
Does Google treat 404 and 410 response codes differently?
Historically Google spokespersons have made it clear that there are small differences in the way that 404 and 410 URLs are treated.
But it has never been clear how differently they're treated.
As recently as last year John Mueller of Google confirmed that using either 404 or 410 response codes for deleted pages is fine.
In most cases, this is great advice.
Odds are that if you’re only interested in increasing your search rankings, there are a million and one other things that you or your SEO company need to be thinking about, working on and improving instead of worrying about how Google is handling 404 and 410 response codes.
However, for those SEO and data geeks out there, this is still a fascinating subject to think about and explore.
Especially since John Mueller has also previously stated that yes, 410 responses can be seen as “more permanent” and work faster than 404 ones.
But how much faster and more permanent?

So, with very limited data orginally available on this topic, we (led by one of our in-house SEO experts Lee Kirby) decided to put the two response codes to the test and see exactly how Google handles them in our latest controlled technical SEO experiment.
Background on Hypertext Transfer Protocol (HTTP) & Response Status Codes
For those not familiar with hypertext transfer protocol (HTTP), this is what handles interactions between browsers and websites.

Tim Berners-Lee, the British computer scientist widely known as the inventor of the World Wide Web who also introduced HTTP as a web standard in 1991. Source: CERN.
The protocol was first introduced in 1991 by Tim Berners-Lee and his team, and it quickly became the official web standard.
These days virtually all web traffic is using HTTP.
Whilst it has evolved over the years, it still forms a core part of the foundation of the World Wide Web even today.
As well as helping us access and experience websites via their browsers, the protocol is also used by search engines in creating their index and by developers for a huge range of other tasks, projects and applications.
Response Status Codes
A HTTP response status code indicates whether a HTTP request was completed successfully and, if not, provides information on why it wasn’t.
There are many response status codes which you can explore in more detail here, but for this experiment we wanted to focus on two key ones, 404 and 410 response codes.
The 404 Response Code
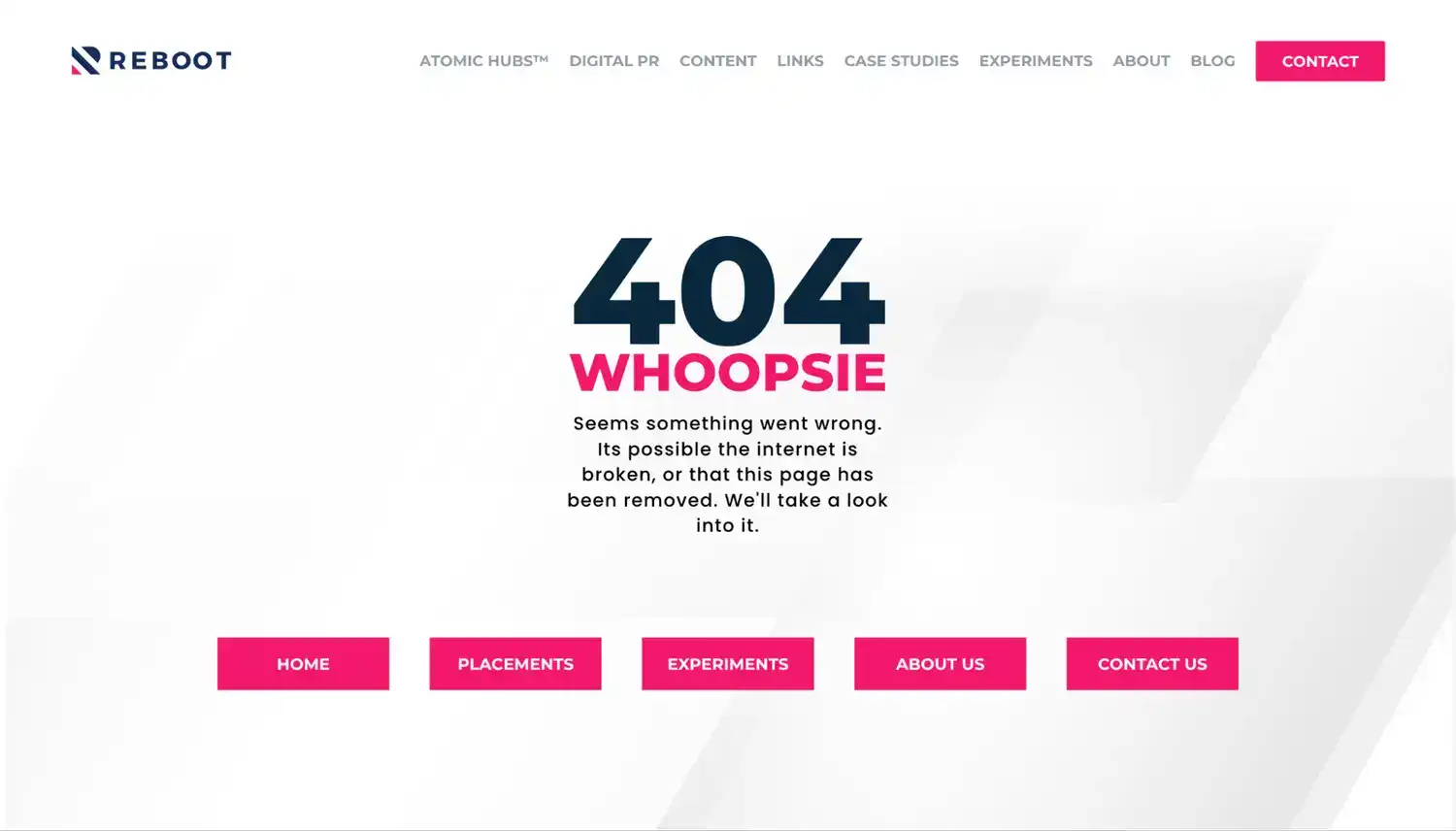
An example of a 404 response code when browsing the web.
The 404 response code might be one of the most well known since it is seen so frequently when browsing the web.
Essentially this means that the server could not locate and/or return the requested resource.
In your browser the requested URL will not be recognised and, these days, it is common to see some content on the page explaining that the request returned a 404 error and perhaps even some hyperlinks to other helpful pages and/or more information.
The 410 Response Code
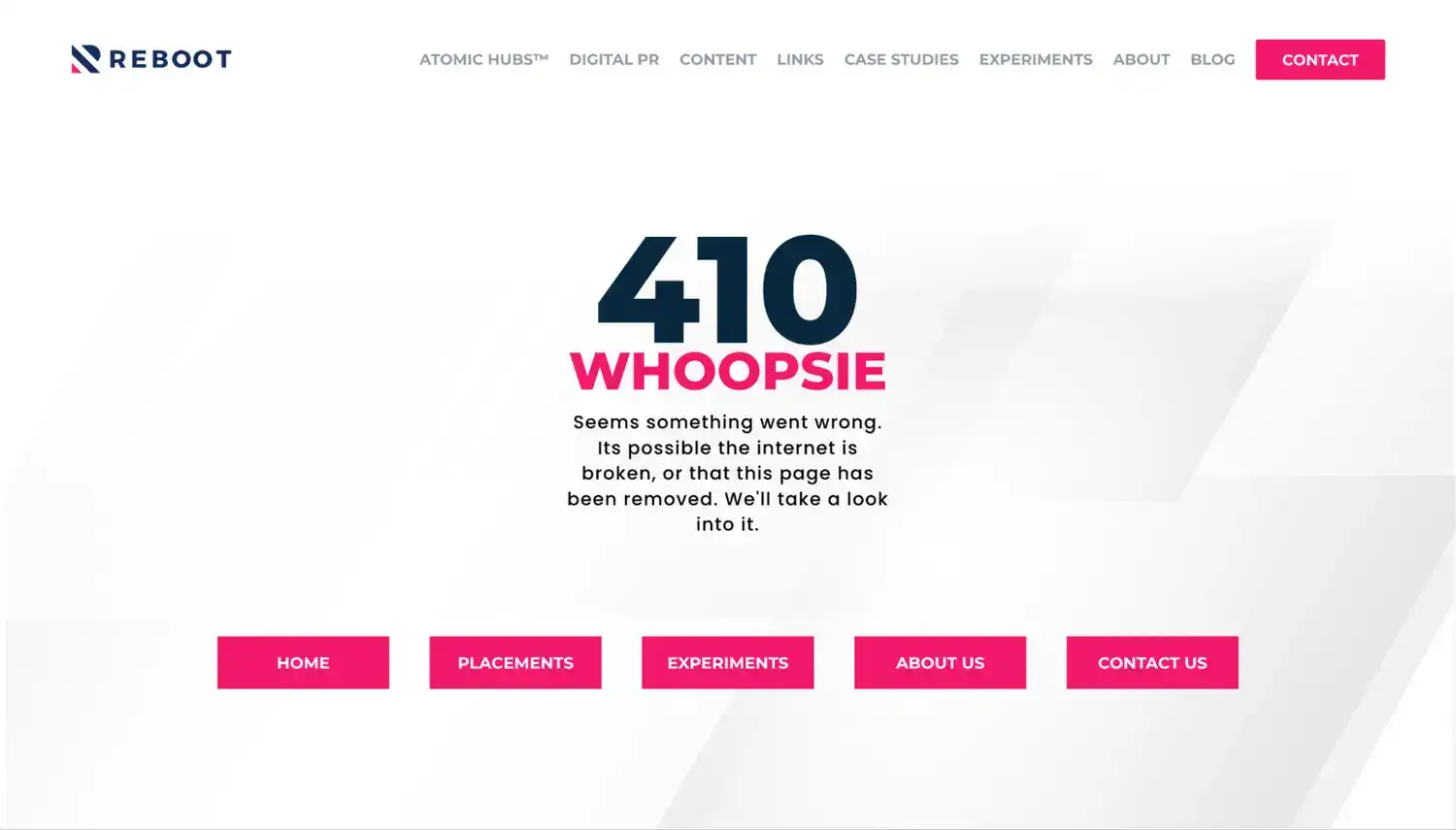
An example of a 410 response code when browsing the web.
The 410 response code on the other hand is returned when the requested content has been permanently removed or deleted from the server (with no forwarding/redirect address).
In many cases it is common to also see some content shown in your browser even when a 410 response is returned.
Why They Matter

When building, maintaining and growing a website you will have to make decisions on how to best handle pages that become obsolete and need to be removed.
In such cases you can delete them and choose to return a number of different response codes to signal to users and search engines that the page(s) no longer exists.
Generally developers will choose to return either a 404 response code or a 410 one when a page is intentionally deleted, assuming they are not forwarding/redirecting it to another relevant URL.
If though, as we saw in John Mueller’s earlier comments, a 410 response could result in the deleted content being removed from the index faster and being recrawled less frequently in the future, it would be technically best to return the proper 410 response code rather than the 404 one when it is possible to do so.
Which response code to use for the quickest result would also be particularly useful to know when talking about a hacked website.
Even if, for most websites, shaving a couple days off the time that it would take for deleted but still indexed URLs to be removed from the index and reducing the average number of recrawls in the short-to-mid term won’t make much difference, using a 410 to get any indexed spam pages created in a hack removed from the index and recrawled less frequently that slightest bit quicker may bring about some peace of mind and comfort.
Also for larger sites, particularly when things like crawl budgets start needing at least some care and attention, returning the best response code for the content being requested would make sense and could even help with crawl budget optimisation and allocation.
So, whilst tweaking how 404 and 410 URLs are handled is unlikely to be of any high priority for most websites, there are some cases where knowing which one is technically correct could come in handy.
Below we cover our hypothesis, the experiment methodology and the results.
Hypothesis
Our hypothesis was that deleted URLs that returned a 410 response code would be recrawled less frequently and removed from Google’s index quicker than deleted URLs returning a 404 response code.
Given that the 410 response code is returned to signal that the requested content has been permanently removed, whilst a 404 response code could be due to a temporary error or mistake, you would expect a search engine bot to react in removing the 410 page from their index and priority recrawl que quicker than they would react to finding a 404 page.
Methodology
In order to effectively test our hypothesis, we would need to observe and measure how frequently the Googlebot came back to crawl a sample of 410 URLs compared to a sample of 404 ones, and also how fast the URLs in each sample were removed from the index.
Now, crawl rates can differ depending on and be influenced by many factors, so we would also have to take these into account and minimise outside variables to the best of our ability whilst running this experiment.
Experiment Methodology
- Identify 2 test websites which have active, indexed URLs.
- Get access to log files and start archiving them.
- Using the Google Search Console API, setup hourly checks to find out if (and when) the sample URLs we intend to use in the experiment are still indexed, and when Google last crawled them.
- Crawl the test websites and identify the indexed URLs that have no external links.
- Of those indexed URLs with no external links, select those with either no internal links at all, or URLs with consistent internal links (the same number of internal links from the same exact pages) that can be compared.
- Set half of the indexed URL sample to 404, and the other half to 410.
- Observe how frequently Google recrawls the various URLs.
- Observe how quickly the URLs return a Coverage State from the GSC API that suggests that they are no longer indexed.
- Compare the data collected from the 404 sample URLs and the 410 ones.
Below are a few of the things that we had to consider whilst setting up and running this experiment, and how we sought to mitigate any outside influence on the results.
Minimising Outside Factors
1. External Links
One of the main ways that Google finds new content to crawl (and old content to recrawl) is by following links found on a web page or document.
It is widely accepted that websites with a greater number of external backlinks will be crawled more frequently, especially when those backlinks are coming from highly crawled websites.
To minimise the effect and influence of external links on our results, we selected URLs in our samples that had, at the time of checking, no external links pointing at them.
Throughout the experiment we also ensured no new links where created or earned on behalf of the websites.
2. Internal Links
Google and other search engines also use internal backlinks to find and crawl new content, or to recrawl old/existing content.
URLs with more internal links pointing to them are likely to be discovered more frequently by search engine spiders and crawled more frequently as a result.
In order to minimise this outside variable and influence we selected and observed only URLs that had either no internal links pointing to them at all, or the same internal links.
We used the Screaming Frog SEO spider tool to generate a list of URLs that met this criteria.
We could then run our comparisons across like-for-like pages (e.g. compare the data for all the URLs with no internal links, then compare the data for URLs with the same 3 internal links etc.).
3. No Other Changes to Experiment Sites in The Testing Period
It was important that throughout the experiment we did not change anything on either test site that could encourage a change in the crawling of them.
Outside of the SEO and web development team, no one knew the experiment sites being used and we confirmed that no ongoing or planned projects related to them.
4. Speed & Usability - Having Both Response Codes on The Same Websites
Originally we thought maybe we could have one website return only 404 response codes, and the other 410 ones.
However we soon realised that this could introduce a number of factors outside of our control related to the speed and usability of each site that would impact their crawlability. By having 50% of the sample URLs on each domain set to 404, and the other 50% set to 410, we ensured that any usability and speed differences between the 2 domains wouldn’t muddy the data.
Any positive or negative UX or speed issues effecting either domain would, in theory, effect the 404 and 410 URLs on each site in the same way.
5. Preexisting Differences in Crawl Rates

It was important to find out if there were any differences in the crawl rates of our sample URLs before we changed them to return the 404 or 410 response codes.
This would allow us to spot early on if actually those we planned to set to 410 were already being crawled less frequently than the 404 ones.
Our checks showed that this wasn’t the case.
In fact, on average the 410 sample URLs were being crawled slightly more frequently than the 404 ones.
Key Obstacles
Being the first experiment of this kind that we have run (our others have focused on artificial keywords + search engine result pages and ranking factors), we were always going to run into a couple of unforseen obstacles.
In the interest of transparency, we wanted to include the details of these obstacles and how we tackled them to ensure the validity and accuracy of the experiment.
Log Files
We intended to collect and save the log files of both sites throughout the experiment. This would allow us to cross compare any data from the Google Search Console API with our own server data.
However, a configuration error meant that the log files were only being saved and stored for a 14 day rolling period.
After 2 weeks of the experiment we no longer had accurate weblog data for the first day of the test.
This meant that, even if after we realised that this was happening we fixed the configuration to save all weblog events, we would still be missing some key data.
So, we cross compared the last crawled time in Google Search Console API data with the weblog data that we did have to confirm that they matched, which they did. We also carried out further random spot checks to reconfirm which also showed that the GSC and weblog data matched exactly.
Google Search Console 'Coverage State'
Originally we wanted to measure and observe both how frequently Google recrawled the 404 and 410 URLs, and how quickly they were removed from the index.
Using the Google Search Console API, we were pulling the ‘CoverageState’ of each URL to determine if it was still indexed.
We anticipated that, once removed from the index, the coverage state of each URL would be changed to one of the applicable labels like ‘crawled, currently not indexed’.
However, a few days into the experiment we found that all of the removed URLs were showing the ‘Not Found (404)’ label as the CoverageState regardless of their response codes (even the 410 URLs were returning a 'Not Found (404)' CoverageState).
The problem was that this label didn’t actually say specifically if the URLs were still indexed or not.
In many cases a manual check with a site command showed that the URLs being marked by Google Search Console as a 404 error were indeed still in the index.
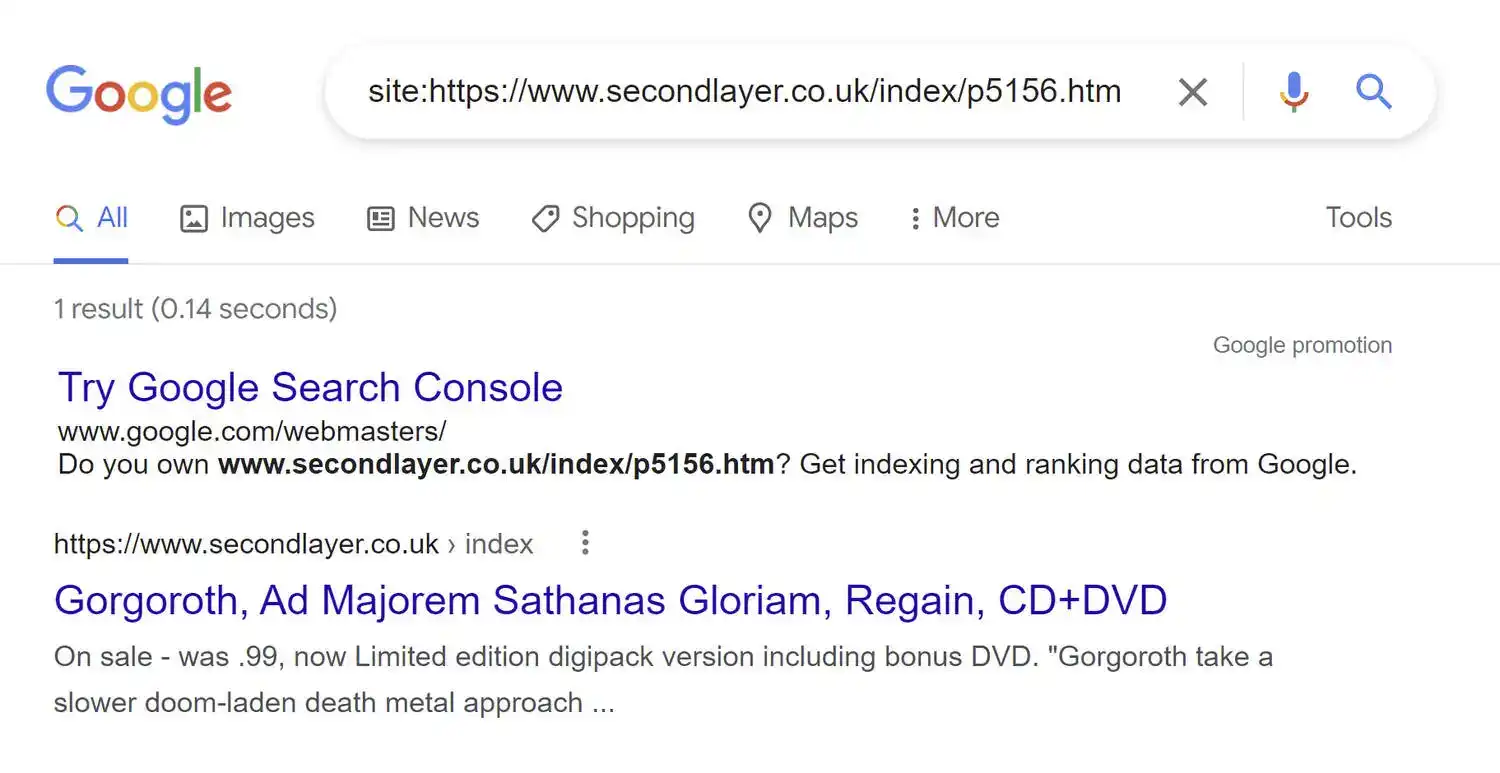
This meant that the API wasn’t going to actually tell us when each URL was removed from the index.
Upon finding this out we decided to focus the entirety of the experiment on the crawl frequency of the sample URLs.
Results

After observing the test sites for more than 3 months, we brought the experiment to a close.
It became apparent that there were unlikely to be any further changes to the coverage state of the sample URLs, and that we had more than enough data on how frequently the URLs were being crawled to gain some insights.
We had over 350,000 rows of data to analyse and digest in order to find out if Google was crawling the 404 URLs more than they were crawling the 410 ones.
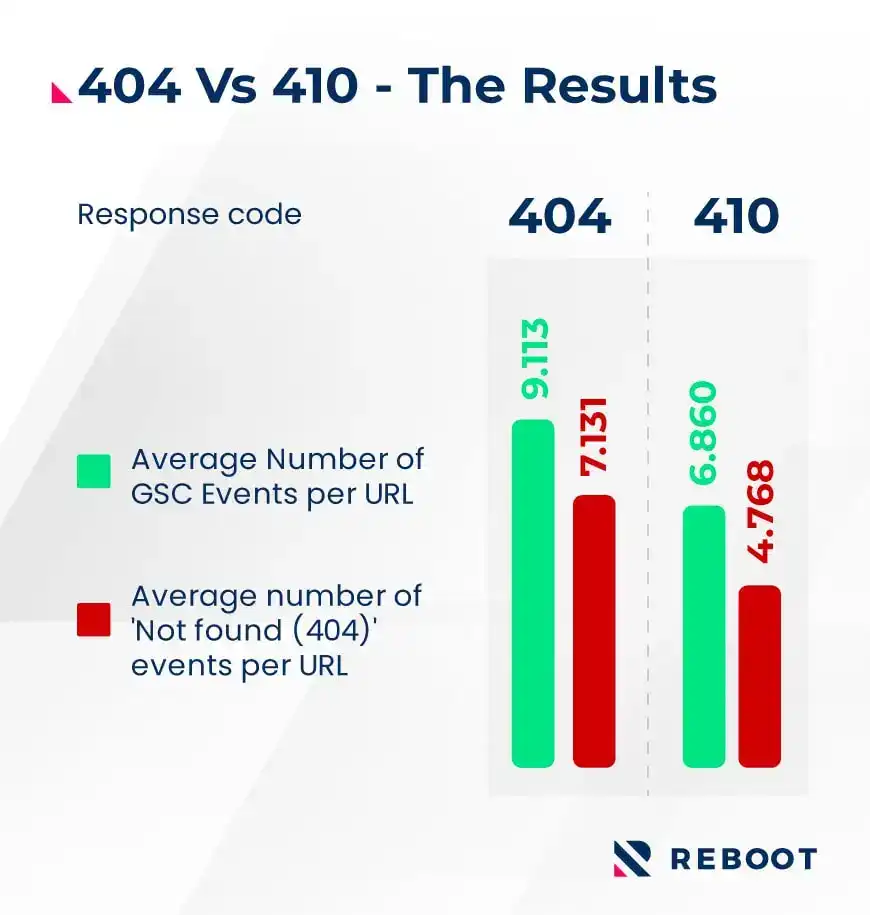
Our data lead Ali ran the numbers and found that yes, the data does show that 404 URLs are crawled more frequently than 410 ones.
Here are some of his comments on the results:
“An analysis of the Google Search Console API data looking at our sample of 119 test web pages shows that 404's are, on average, crawled 49.6% more often than 410's."
We also compared the results after breaking the sample URLs down by internal link counts:
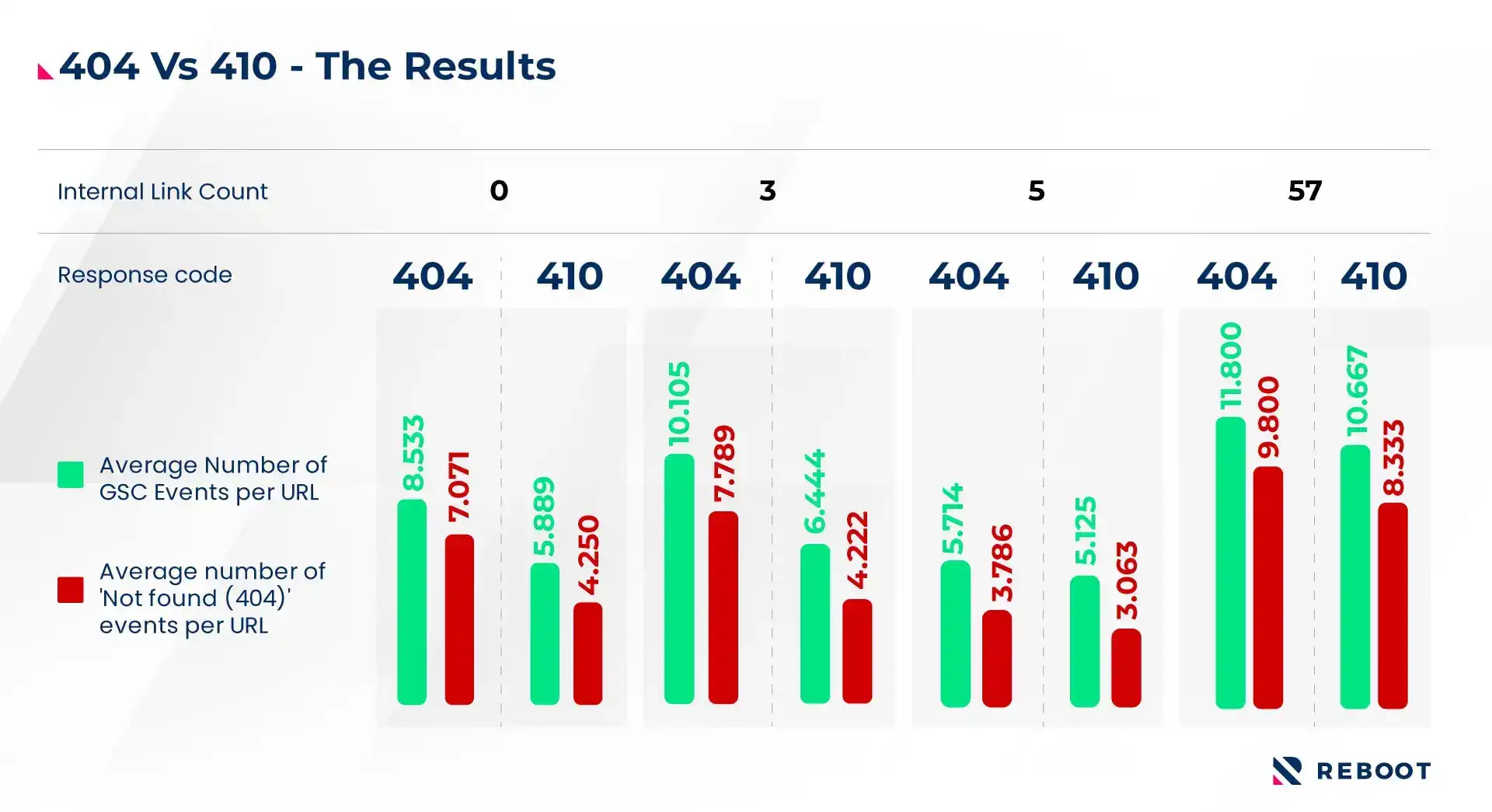
Ali added:
"This trend is also consistent amongst strata of our sample grouped on the basis of internal backlink counts. A T-test confirms the statistical significance of our overall results to within 95% confidence.
While both analyses confirm our initial hypothesis, the latter lacks sufficient sample sizes for conclusive results to be ascertained for each stratum, the overall trend however, is indicative.”
Kevin Indig, Director of SEO at Shopify, took an early look at the write up and results and shared his thoughts:
"410 are treated like 301s and 404 like 302s. It makes sense that 404s are more often recrawled by Google because Google expects that the 404 turns into a 200 or 410 again."
Summary
This was a very challenging experiment to run, and being the first of its kind some unforseen issues did come up which will help us better plan our metholodogies in future experiments.
A 49.6% difference in how frequently the 404 URLs were crawled compared to the 410 ones though is a very interesting and conclusive result.
The data from this study does suggest that if you want Google to recrawl a removed URL as infrequently as possible, you should go with a 410 response code over a 404 one.
Thanks
These experiments require a lot of time and resources from many of the team at Reboot, and in this case Lee Kirby (who took the lead on the technical setup of the experiment), our data lead Ali Hassan, web developer Ledi Salillari, managing director Shai Aharony, and graphic designers Scott Bowman and Anastasia Davies all helped put it together. Also to our wider digital PR agency and SEO company team who help support and promote all of our SEO experiments.
We also want to say a quick thank you to Kevin Indig, SEO Director at Shopify and host of the Tech Bound podcast, for adding his comments on the results and taking an early look at the write up.